Vai al contenuto
Vai al contenuto

Il contesto attuale a livello aziendale è sempre più caratterizzato da un forte e continuo cambiamento. Questo aspetto è ancora più evidente che nel modo in cui le organizzazioni consumano i dati.
Una tipica azienda, a seconda della proprie dimensioni, può avere decine se non addirittura migliaia di analisti e utenti aziendali che accedono quotidianamente alle dashboard, data scientist che sviluppano e addestrano modelli e un team di data engineer che progettano ed eseguono pipeline di dati.
Ognuno di questi carichi di lavoro ha esigenze di calcolo e di storage differenti e distinte, che possono cambiare in modo significativo di ora in ora e di giorno in giorno. La sfida di ogni azienda consiste nel garantire che ognuno di questi carichi di lavoro sia veloce, stabile ed efficiente.
Cosa significa efficienza?
Per efficienza intendiamo l’essere in grado di fornire le migliori prestazioni al costo più basso, riducendo al contempo gli sprechi.Purtroppo, le piattaforme dati legacy sono l’emblema dello spreco e dell’inefficienza.
Le loro risorse fisse sono dimensionate per soddisfare i picchi di domanda, il che significa che per la maggior parte della giornata gran parte delle loro risorse sono inattive e comportano costi.D’altra parte, query complesse o picchi di utilizzo causano colli di bottiglia perché non sono in grado di scalare istantaneamente per soddisfare la domanda aziendale.
E in Snowflake?
Sappiamo che la piattaforma di Snowflake è diversa. Abbiamo imparato a conoscere Snowflake e le sue caratteristiche distintive. Sappiamo che come servizio a consumo, i clienti hanno accesso a un insieme virtualmente illimitato di risorse che possono essere attivate quasi istantaneamente, ma anche ridimensionate automaticamente o spente completamente quando non sono più necessarie. Questa elasticità istantanea offre la flessibilità necessaria per adattare le risorse alle esatte esigenze di ogni utente, team, reparto e carico di lavoro ogni secondo della giornata. Questo si applica anche allo storage, al calcolo e alle attività serverless; ogni risorsa può essere scalata in modo indipendente. Il risultato è che i clienti Snowflake pagano solo per le risorse di cui hanno bisogno, quando ne hanno bisogno, massimizzando l’efficienza e riducendo al minimo gli sprechi e i costi.
Qui di seguito presentiamo alcune delle best practice individuate da David A. Spezia, Senior Sales Engineer di Snowflake.
Best Practice #1: Abilitare Auto-Resume
Assicuratevi che tutti i virtual warehouse abbiano la funzionalità Auto-Resume abilitata. Se si intende implementare la sospensione automatica e impostare limiti di timeout appropriati, l’abilitazione della ripresa automatica è indispensabile; in caso contrario, gli utenti non saranno in grado di interrogare il sistema.
Attraverso la seguente query è possibile individuare i Warehouse che non hanno Auto-Resume impostato:
SHOW WAREHOUSES
;
SELECT "name" AS WAREHOUSE_NAME
,"size" AS WAREHOUSE_SIZE
FROM TABLE(RESULT_SCAN(LAST_QUERY_ID()))
WHERE "auto_resume" = 'false'
;
Abilitando questa funzione, un warehouse viene ripreso automaticamente ogni volta che viene inviata una query su quel warehouse specifico.
Di default, tutti i warehouse hanno l’Auto-Resume abilitato.
Best Practice #2: Abilitare Auto-Suspend
Assicuratevi che tutti i virtual warehouse siano impostati sulla modalità Auto-Suspend. In questo modo, quando hanno finito di elaborare le query, la sospensione automatica spegnerà i virtual warehouse, interrompendo così il consumo di credito.
Tramite la seguente query è possibile identificare tutti i warehouse che non hanno la sospensione automatica abilitata.
SHOW WAREHOUSES
;
SELECT "name" AS WAREHOUSE_NAME
,"size" AS WAREHOUSE_SIZE
FROM TABLE(RESULT_SCAN(LAST_QUERY_ID()))
WHERE IFNULL("auto_suspend",0) = 0
;
Per impostazione predefinita, tutti i virtual warehouse hanno la sospensione automatica attivata.
Best Practice #3: Impostare un Timeout appropriato per i diversi Workloads
Tutti i virtual warehouse devono avere un timeout appropriato per il loro particolare carico di lavoro:
- Per i virtual warehouse di attività, caricamento dei dati e ETL/ELT, è buona pratica impostare il timeout per la sospensione immediatamente dopo il completamento;
- Per i virtual warehouse di BI e di query SELECT, il timeout di sospensione dovrebbe essere impostato a 10 minuti nella maggior parte delle situazioni per mantenere “attiva” la cache dei dati;
- Per i virtual warehouse DevOps, DataOps e Data Science, impostare il timeout di sospensione a 5 minuti, perché la cache non è così importante per le query uniche e ad hoc.
La seguente query identifica i virtual warehouse che hanno l’impostazione più lunga per la sospensione automatica dopo un periodo di inattività su quel warehouse:
SHOW WAREHOUSES
;
SELECT "name" AS WAREHOUSE_NAME
,"size" AS WAREHOUSE_SIZE
FROM TABLE(RESULT_SCAN(LAST_QUERY_ID()))
WHERE "auto_suspend" >= 3600// 3600 seconds = 1 hour
;
Best Practice #4: Usare il Resource Monitor
Il Resource Monitor permette di monitorare e gestire l’utilizzo delle risorse all’interno di Snowflake.
Fornisce informazioni dettagliate sulle risorse utilizzate, come ad esempio la quantità di storage utilizzata, il numero di warehouse in esecuzione e l’utilizzo di crediti. Inoltre, è possibile impostare avvisi e limiti sull’utilizzo delle risorse per mantenere il controllo sui costi e sulla performance.
In particolare, il Resource Monitor è uno strumento importante per gli amministratori di sistema, i responsabili IT e gli utenti finali di Snowflake, che desiderano monitorare e ottimizzare l’utilizzo delle risorse.
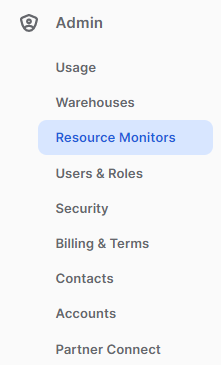
Per accedere al Resource Monitor bisogna cliccare sulla Tab Admin, Resource Monitors:
e da qui, cliccare sul pulsante blu in alto a destra:
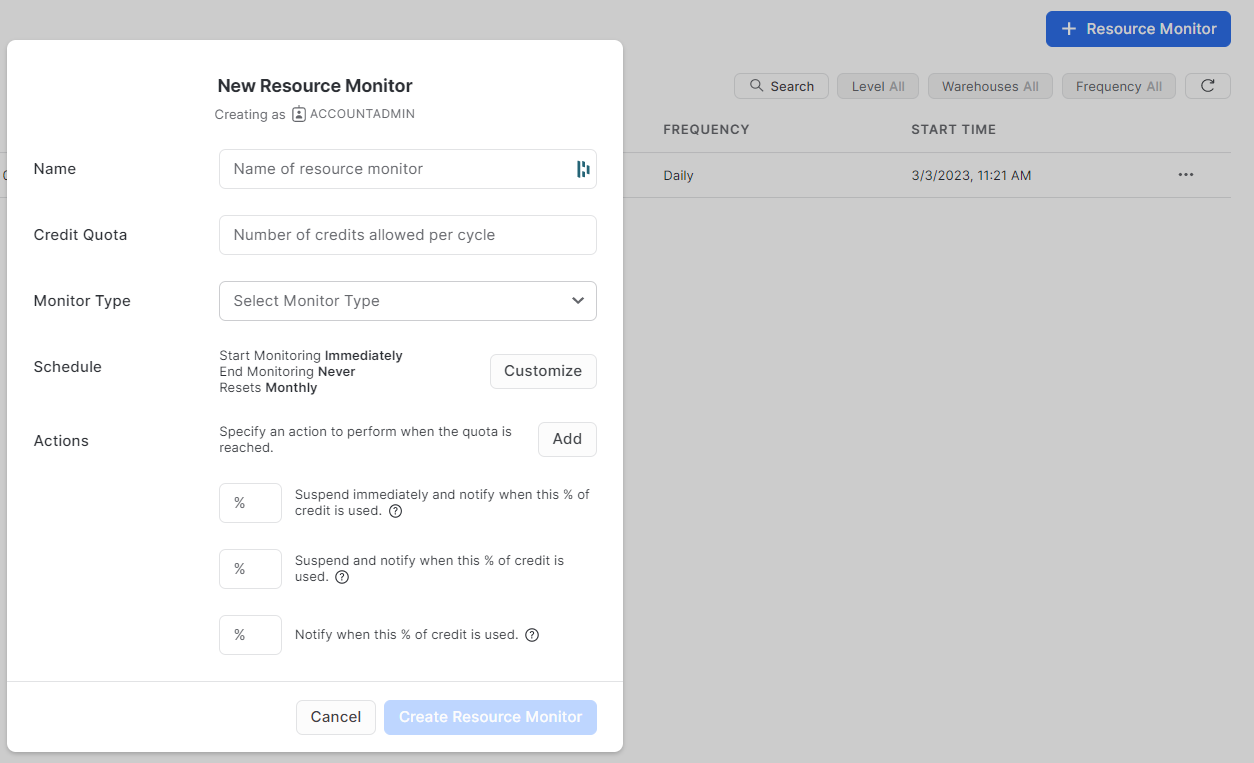
Utilizzando la seguente query è possibile individuare tutti i warehouse che non dispongono del Resource Monitor.
SHOW WAREHOUSES
;
SELECT "name" AS WAREHOUSE_NAME
,"size" AS WAREHOUSE_SIZE
FROM TABLE(RESULT_SCAN(LAST_QUERY_ID()))
WHERE "resource_monitor" = 'null'
;
In sintesi quindi il monitoraggio delle risorse consente di fissare dei limiti ai crediti consumati da un warehouse durante uno specifico intervallo di tempo. In questo modo si può evitare che alcuni warehouse consumino involontariamente più crediti di quelli previsti.
Best Practice #5: User Segmentation
Può essere utile andare a segmentare i ruoli all’interno di Snowflake. Infatti, se i tempi di esecuzione o il conteggio delle query tra i ruoli all’interno di un singolo warehouse sono estremamente diversi, potrebbe valere la pena di segmentare gli utenti in warehouse separati e configurare ciascun warehouse per soddisfare le esigenze specifiche di ciascun workload.
La seguente query elenca tutti i warehouse utilizzati da più Ruoli in Snowflake e restituisce il tempo medio di esecuzione e il conteggio di tutte le query eseguite da ogni Ruolo per ogni warehouse:
SELECT *
FROM (
SELECT
WAREHOUSE_NAME
,ROLE_NAME
,AVG(EXECUTION_TIME) as AVERAGE_EXECUTION_TIME
,COUNT(QUERY_ID) as COUNT_OF_QUERIES
,COUNT(ROLE_NAME) OVER(PARTITION BY WAREHOUSE_NAME) AS ROLES_PER_WAREHOUSE
FROM "SNOWFLAKE"."ACCOUNT_USAGE"."QUERY_HISTORY"
where to_date(start_time) >= dateadd(month,-1,CURRENT_TIMESTAMP())
group by 1,2
) A
WHERE A.ROLES_PER_WAREHOUSE > 1
order by 5 DESC,1,2
;
Best Practice #6: Impostare gli Account Statement Timeouts
Un’altra buona pratica consiste nell’impostare e personalizzare gli statement a livello di timeouts per quanto riguarda warehouse, account, sessioni e user, in base alla strategia dei dati per le query di lunga durata.
Si possono usare i parametri STATEMENT_QUEUED_TIMEOUT_IN_SECONDS e STATEMENT_TIMEOUT_IN_SECONDS per interrompere automaticamente le query che richiedono troppo tempo per essere eseguite, a causa di un errore dell’utente o di un cluster bloccato.
Qui di seguito un esempio dei diversi parametri:
SHOW PARAMETERS LIKE 'STATEMENT_TIMEOUT_IN_SECONDS' IN ACCOUNT;
SHOW PARAMETERS LIKE 'STATEMENT_TIMEOUT_IN_SECONDS' IN WAREHOUSE <warehouse-name>;
SHOW PARAMETERS LIKE 'STATEMENT_TIMEOUT_IN_SECONDS' IN USER <username>;
Best Practice #7: Identificare i Warehouses che variano dalla media dei 7 giorni
Quando si è impegnati in progetti di lunga durata, può essere difficile tenere traccia dei dati relativi all’utilizzo del credito, soprattutto nei casi in cui il credito supera l’importo desiderato. Un metodo utile è quello di creare una query che controlli la media di sette giorni di utilizzo del credito e scopra le settimane che superano l’utilizzo. Questo metodo può fornirvi indicazioni utili sulle attività che occupano troppo spazio e tempo, ma che non vengono eseguite in modo efficiente.
Potete eseguire questa query ogni mattina per verificare i warehouse che variano dalla media di 7 giorni di utilizzo del credito:
SELECT WAREHOUSE_NAME, DATE(START_TIME) AS DATE,
SUM(CREDITS_USED) AS CREDITS_USED,
AVG(SUM(CREDITS_USED)) OVER (PARTITION BY WAREHOUSE_NAME ORDER BY DATE ROWS 7 PRECEDING) AS CREDITS_USED_7_DAY_AVG,
(TO_NUMERIC(SUM(CREDITS_USED)/CREDITS_USED_7_DAY_AVG*100,10,2)-100)::STRING || '%' AS VARIANCE_TO_7_DAY_AVERAGE
FROM "SNOWFLAKE"."ACCOUNT_USAGE"."WAREHOUSE_METERING_HISTORY"
GROUP BY DATE, WAREHOUSE_NAME
ORDER BY DATE DESC;
Best practice #8: Monitorare i warehouse che si avvicinano alla soglia di fatturazione dei servizi cloud
La seguente query esamina i warehouse in cui i costi dei servizi cloud rappresentano un’alta percentuale del carico di lavoro.
In generale per un account, Snowflake addebiterà i servizi cloud solo se superano il 10% del consumo giornaliero di credito del warehouse virtuale. Le attività dei servizi cloud sono utili per le operazioni sui metadati, come le query di scoperta degli strumenti di BI, le query heartbeat, i comandi SHOW, l’uso della cache e molte altre funzioni di ottimizzazione dei servizi.
Questa query aiuta a capire quali virtual warehouse si avvicinano o superano la soglia del 10%:
WITH
cloudServices AS (SELECT
WAREHOUSE_NAME, MONTH(START_TIME) AS MONTH,
SUM(CREDITS_USED_CLOUD_SERVICES) AS CLOUD_SERVICES_CREDITS,
COUNT(*) AS NO_QUERYS
FROM "SNOWFLAKE"."ACCOUNT_USAGE"."QUERY_HISTORY"
GROUP BY WAREHOUSE_NAME,MONTH
ORDER BY WAREHOUSE_NAME,NO_QUERYS DESC),
warehouseMetering AS (SELECT
WAREHOUSE_NAME, MONTH(START_TIME) AS MONTH,
SUM(CREDITS_USED) AS CREDITS_FOR_MONTH
FROM "SNOWFLAKE"."ACCOUNT_USAGE"."WAREHOUSE_METERING_HISTORY"
GROUP BY WAREHOUSE_NAME,MONTH
ORDER BY WAREHOUSE_NAME,CREDITS_FOR_MONTH DESC)
SELECT *, TO_NUMERIC(CLOUD_SERVICES_CREDITS/NULLIF(CREDITS_FOR_MONTH,0)*100,10,2) AS PERCT_CLOUD
FROM cloudServices
JOIN warehouseMetering USING(WAREHOUSE_NAME,MONTH)
ORDER BY PERCT_CLOUD DESC;
Best practice #9: Eliminare le tabelle inutilizzate
Non è infrequente il caso in cui vi siano delle tabelle inutilizzate. È buona prassi eliminare queste tabelle e assicurarsi che nessun utente esegua query su di esse.
Un ulteriore buona prassi potrebbe essere quella di rendere obbligatorio il controllo di tutte le tabelle prima della loro eliminazione.
Utilizzando questo script SQL:
SHOW STREAMS;
select *
from table(result_scan(last_query_id()))
where "stale" = true;
è possibile identificare le tabelle non utilizzate.
Best practice #10: Eliminare gli “inattivi” utenti/ruoli inattivi o che non hanno mai fatto login
È una buona idea eliminare dal proprio account gli utenti inattivi o quelli che non hanno mai effettuato l’accesso a Snowflake.
- Eliminare gli utenti inattivi
SELECT
*
FROM SNOWFLAKE.ACCOUNT_USAGE.USERS
WHERE LAST_SUCCESS_LOGIN < DATEADD(month, -1, CURRENT_TIMESTAMP())
AND DELETED_ON IS NULL;
Utenti della piattaforma Snowflake che non hanno effettuato il login negli ultimi 30 giorni.
- Utenti che non hanno mai effettuato il login
SELECT
*
FROM SNOWFLAKE.ACCOUNT_USAGE.USERS
WHERE LAST_SUCCESS_LOGIN IS NULL;
- Warehouse inattivi
SELECT
R.*
FROM SNOWFLAKE.ACCOUNT_USAGE.ROLES R
LEFT JOIN (
SELECT DISTINCT
ROLE_NAME
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY
WHERE START_TIME > DATEADD(month,-1,CURRENT_TIMESTAMP())
) Q
ON Q.ROLE_NAME = R.NAME
WHERE Q.ROLE_NAME IS NULL
and DELETED_ON IS NULL;
Ed eccoci arrivati alla Best Practice +1:
Best practice +1: Utilizzare una dashboard Tableau (o un qualsiasi altro strumento di BI partner di Tableau)
Come undicesima best practice bonus, è sempre utile creare delle dashboard che permettano di monitorare l’utilizzo di Snowflake. Se volete saperne di più, vi invitiamo a leggere un nostro post scritto in precedenza qui.
Sappiamo inoltre che Tableau ha messo insieme una serie di dashboard che mostrano l’utilizzo del credito, le prestazioni e l’adozione della piattaforma da parte degli utenti.
A questo link è possibile scaricare il workbook già costruito.
Conclusione Grazie all’elevata elasticità del calcolo e al modello di fatturazione al secondo di Snowflake, gli amministratori degli account dovrebbero monitorare costantemente l’utilizzo, la crescita e l’efficienza delle risorse per assicurarsi che corrispondano ai requisiti di performance e al budget. Anche se Snowflake può aiutare a ottimizzare le risorse in modo automatico, gli amministratori degli account hanno la possibilità di mettere a punto ulteriormente la loro distribuzione, soprattutto quando la loro impronta di calcolo cresce. Raccomandiamo di implementare queste best practice di base per monitorare e ottimizzare le risorse su Snowflake, ed evitare le insidie più comuni che possono presentarsi.
Fonti: https://www.snowflake.com/blog/understanding-snowflakes-resource-optimization-capabilities/
https://www.snowflake.com/blog/10-best-practices-every-snowflake-admin-can-do-to-optimize-resources/