 Vai al contenuto
Vai al contenuto

Abbiamo visto nel precedente articolo le procedure di automatizzazione e condivisione in Trifacta. In questo breve articolo, invece, ci concentreremo su best practices e use cases in Trifacta, vedendo insieme alcune linee guide da seguire per ottimizzare i recipe in modo che siano efficienti e performanti.
Un recipe ottimizzato può fare la differenza in termini di tempo di esecuzione, risorse utilizzate e in generale la stabilità dei lavori prodotti.
Ogni step aggiunto al recipe rappresenta una serie di calcoli che richiedono un certo ammontare di risorse per il motore di calcolo della piattaforma. Alcuni step sono combinati da un ottimizzatore, ma grazie alla flessibilità offerta da Trifacta nel design dei nostri recipe, alcuni accorgimenti possono generare un maggiore impatto positivo sulle performance.
I fattori che influenzano maggiormente le performance sono 3:
1 Il numero degli step
2 La grandezza del dataset
3 La complessità di ogni step del recipe che impatta sulla durata del processo di calcolo
Numero degli step
Il primo fattore da considerare è dunque il numero di step che usiamo nel flow. Quando eseguiamo un flusso, come già accennato, Trifacta cerca di ottimizzare i calcoli il più possibile combinando alcuni step, ma in linea generale il numero di calcoli da processore aumentano linearmente all’aumentare del numero di recipe. Di conseguenza diminuire il numero di step può migliorare di molto le performance. Spesso, soprattutto i nuovi utenti, creano degli step non necessari solamente per provare alcune funzioni ed usando un altro calcolo per tornare alla situazione precedente. In questo modo vengono creati due step inutili ma la piattaforma deve comunque eseguire questi calcoli. Per questo è importante cercare sempre di mantenere solo gli step che sono veramente necessari per ottenere l’output desiderato.
Un altro modo per ridurre il numero degli step è quello di cercare di utilizzare più funzioni nello stesso calcolo per effettuare alcune trasformazioni. Trifacta offre una grande varietà di funzioni e tool che possono aiutare a raggiungere i risultati desiderati in diversi modi. Il consiglio è di pensare sempre a soluzioni alternative che richiedano meno passaggi quando ci accorgiamo di utilizzare molti step.
La grandezza del Dataset
Il secondo fattore che impatta sulla performance è certamente la grandezza del dataset. Più colonne abbiamo e più risorse la piattaforma dovrà utilizzare per eseguire l’intero processo. Lavorando con Trifacta la best practice è sempre quella di ridurre al minimo le colonne del dataset mantenendo solo quelle essenziali per il nostro output. Quando si utilizzano dataset, ad esempio, con 100 colonne ma il nostro output ne richiede solo 15, la cosa da fare per minimizzare le risorse utilizzate e migliorare l’efficienza è quella di ridurre il numero di colonne come primo step. In questo modo si evita di sprecare tempo e risorse portandosi dietro colonne inutili fino alla fine del processo.
Per esempio vogliamo sommare 100 ai valori di colA e poi tenere solo colA e colE. In figura 1 possiamo vedere un modo per ottenere la trasformazione desiderata. Lo stesso risultato si può però ottenere in Figura 2 ed è molto più efficiente.
Per esempio vogliamo sommare 100 ai valori di colA e poi tenere solo colA e colE. In figura 1 possiamo vedere un modo per ottenere la trasformazione desiderata. Lo stesso risultato si può però ottenere in Figura 2 ed è molto più efficiente.
FIg. 1
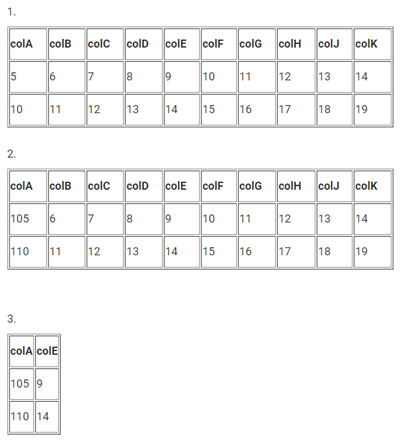
Fig. 2

La complessità di ogni trasformazione
Non tutte le trasformazioni che eseguiamo hanno lo stesso peso sul processo di esecuzione dei flussi. Alcune richiedono molte più risorse computazionali rispetto ad altre. Nella figura qui di seguito possiamo avere un’idea del diverso peso che alcune tra le funzioni più utilizzate hanno sul motore di calcolo di Trifacta.

In generale la best practice da seguire è sempre quella di pensare a soluzioni alternative per ottenere l’output desiderato cercando di utilizzare meno risorse possibili. Spesso è preferibile dividere il dataset in più parti in modo da sviluppare più flow che useranno meno risorse rispetto a un unico flow che effettua trasformazioni su tutto il dataset. Alla fine basterà unire i nostri output per ottenere il risultato finale.
Conclusioni
In conclusione è sempre bene tenere a mente questi tre fattori fondamentali che impattano sulla performance, soprattutto quando lavoriamo su dataset molto grandi. Questi piccoli accorgimenti possono fare la differenza tra un flow lento e inefficiente e un flow ottimizzato e performante e possono permettere di risparmiare molto tempo.
Per ulteriori domande su Trifacta vi invitiamo a contattarci all’indirizzo: info@theinformationlab.it
Speriamo che questo articolo vi abbia incuriosito e che continuiate a seguire il nostro blog. Alla prossima!

