 Vai al contenuto
Vai al contenuto

Uno dei primi problemi in cui ci si imbatte nel lavorare con i dati è sicuramente la preparazione dei dataset, meglio nota come Data Prepping. In questa fase l’idea è di rimuovere dati incorretti, corrotti, non formattati, duplicati o incompleti, in modo da renderli fruibili e adatti ad elaborare modelli il più possibile accurati.
Sembra che la pulizia e l’”interpretazione” dei dataset sia l’operazione meno apprezzata da ogni data scientist o analista di dati, eppure nel Data Prepping risiede il cuore ed il presupposto di qualunque modello predittivo-prescrittivo. Se i dati fossero inesatti o illeggibili, nessun programma o linguaggio di programmazione potrebbe permetterci di estrapolarvi informazioni utili.
Alteryx ci aiuta nel poco entusiasmante compito di unire, modificare e rendere più accessibile uno o più database. Questo a prescindere dalla provenienza (off o in-cloud) o il formato del nostro data source.
Alteryx e il “data prepping”
Uno degli argomenti più spinosi per gli analisti dei dati è la preparazione dei dataset prima di preparare una dashboard. Infatti la maggior parte degli analisti è scoraggiato dall’idea di ripulire dataset con milioni (se non miliardi) di valori. Diciamocelo: la stessa database maintenance è piuttosto noiosa e ripetitiva. Lo stesso vale per i data scientist, che trascorrono anni a cercare i modi più eleganti di scrivere un codice, ma sono restii al “data prepping”.
Alteryx in tal senso risulta estremamente utile e user-friendly. Si può usare con una conoscenza minima dei linguaggi di programmazione e di data wrangling.
Con pochi nodi e semplici funzioni è possibile trasformare, alterare, unire e replicare interi database, lavorando sia in-house che con warehouse e DB in cloud.
La lettura di file .txt e la trascrizione in .csv
Una delle caratteristiche di Alteryx che ho apprezzato di più è stata la rapidità di codifica e di trascrizione dei dataset. L’utilità del programma l’ho scoperta proprio durante il mio master. Infatti, proprio parlando con dei colleghi di corso, ci siamo accorti che un dataset per il nostro capstone project non era il solito .csv, ma il ben più ostico formato .txt. Questo perché il cliente lo aveva prodotto tramite SPSS. Questo software IBM ha un costo abbastanza proibitivo, quindi nessuno di noi di noi si poteva permettere di acquistarlo solo per leggere dei dati.
Ho notato che i miei colleghi provavano un certo sconforto nel lavorare con il formato .txt. Chi ha mai avuto a che fare con questa tipologia di file sa di cosa parlo:
- Centinaia di migliaia di righe disposte in colonne non omogenee;
- Assenza di separatori chiari;
- Spazi eccessivi o al contrario frasi scritte una dopo l’altra con solo un tab a demarcarle;
- Difficoltà nel leggere i dati inseriti e individuare i valori mancanti.
Lavorare con Alteryx mi ha sostanzialmente permesso di decodificare e trascrivere l’intero data set in pochissimi passaggi.
All’inizio, il mio dataset si presentava in questo modo:

Ho deciso di trasportarlo in Alteryx semplicemente trascinando il file nel workflow aperto. A quel punto il programma ha automaticamente individuato il tipo di file come “non riconosciuto”. Dalla finestra pop-up aperta sono riuscita a selezionare la lettura come file di testo delimitato da tab.

Purtroppo però il file si presentava già come un’unica colonna. Si intuiva dall’anteprima che dovevo compiere un altro passaggio per suddividere i field.

Text to columns: ricavare colonne da un unico field
Selezionando il nodo per trasferire il contenuto di una sola colonna in più colonne diverse sono riuscita a dividere l’intero dataset in pochissimi step.
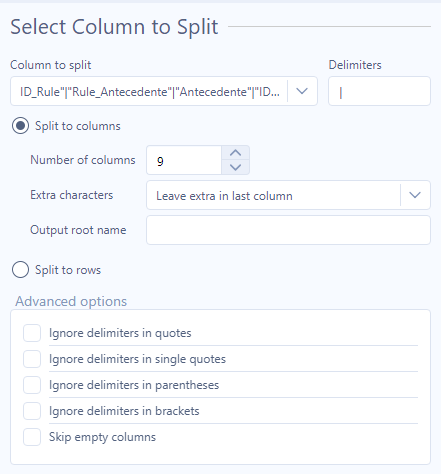
Il nodo Text to columns si trova sotto la sezione Parse e si è rivelato estremamente utile per dividere l’unica colonna in cui si presentava il file. Per separare i valori mi è bastato selezionare il numero di colonne da creare, e usare come delimiter il tab.
Non ho perso tempo a rinominare le nuove colonne che avrei derivato da quella iniziale. Infatti, una volta create le nuove colonne mi è bastato selezionare il nodo Select sotto la sezione Preparation.

Così sono riuscita a rinominare i field a mio piacimento senza modificare il file originale. Mi sono poi assicurata che il data type fosse impostato su V_String e non su altri formati di testo.

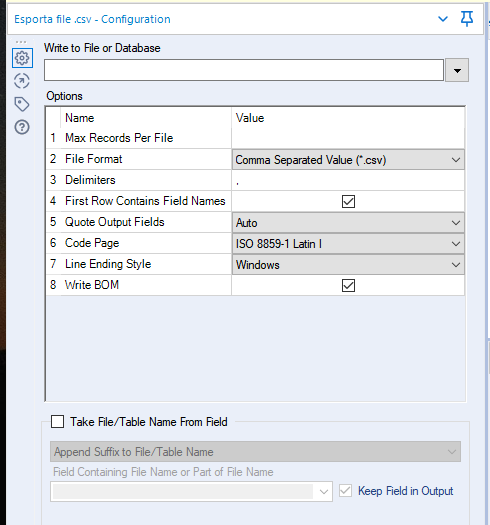
Per concludere, ho usato il nodo Output data per esportare il file in .csv e condividerlo.
In sostanza, Alteryx ha fatto la differenza per me che ho pochissima conoscenza di linguaggi di programmazione. Per questo credo che utilizzarlo può fare la differenza in un progetto. Soprattutto, consiglio l’uso di Alteryx a a chi odia il Data Prepping, perché spiana la strada a infinite possibilità nell’analisi dei dati.
Se desideri ricevere maggiori informazioni su come utilizzare sull’importanza di implementare un sistema di Data Governance all’interno della tua azienda e su Alteryx ti invitiamo a contattarci all’indirizzo: info@theinformationlab.it e a continuare a seguire il nostro blog e le nostre pagine YouTube e LinkedIn.

