 Vai al contenuto
Vai al contenuto

Cominciamo con un esercizio pratico. Proviamo ad utilizzare il metodo che ho descritto nell’ultimo articolo per collezionare le citazioni della pagina http://quotes.toscrape.com/scroll.
Per prima cosa, analizziamo la pagina. Utilizzando gli strumenti per sviluppatori, scopriamo che la parte di codice che racchiude il testo della citazione è racchiuso tra <span class="text"> e </span>:


Tuttavia, se cerchiamo la stringa <span class="text"> nel codice sorgente della pagina non troviamo risultati! Questo è perché la pagina viene generata dinamicamente lato client, ovvero dal browser, e quindi la risposta HTML del server non contiene tutte le informazioni che visualizziamo.
In questi casi possiamo comunque fare lo scraping delle informazioni che ci interessano grazie al Python tool e la libreria Selenium.
Selenium
La libreria Selenium ci consente di automatizzare un browser (Firefox, Chrome, Edge o Safari) e di simulare le interazioni di un utente (click, inserimento di testo, drag and drop, navigazione tra finestre e frame e tanto altro) con un sito o un’applicazione web.
Perciò, quando abbiamo a che fare con un sito generato lato client, Selenium è in grado di estrarre tutto il codice della pagina.
La nostra cassetta degli attrezzi
Oltre ai tool menzionati nell’ultimo articolo, ci servono alcuni altri strumenti:
- Il web driver di vostra scelta, che sia Firefox, Chrome, Edge o Safari;
- Le librerie Python
selenium,urllib3epandas.
Per scaricare il driver potete riferirvi a questa pagina. Una volta fatto, procediamo con l’installazione. Ricordatevi di salvarvi il percorso dell’eseguibile del driver: ci servirà più tardi!
Per installare le librerie che ci servono trasciniamo un Python tool – lo trovate nella tab Developer – sull’area di lavoro. Se avete bisogno di una guida per muovervi nell’interfaccia del tool, potete cliccare su Help e selezionare User Interface Tour:
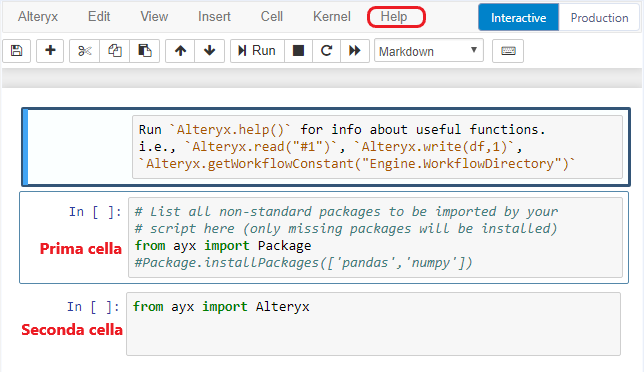
Modifichiamo la prima cella in questo modo e la mandiamo in esecuzione cliccando sul tasto Run:

Ora abbiamo installato le librerie, ma dobbiamo ancora importarle. Per farlo, modifichiamo la seconda cella:
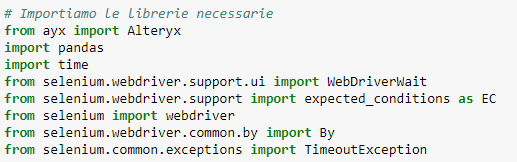
Apertura del browser
Con le righe di codice seguenti, vi farò vedere come:
- Creare un’istanza di web driver Firefox;
- Utilizzare il driver per aprire il link;
- Attendere l’apertura della pagina.
Ora clicchiamo sul bottone + per inserire un’altra cella. Considerate che il tool eseguirà le celle una per volta, in ordine.

Nella cella appena creata, digitiamo il codice seguente:
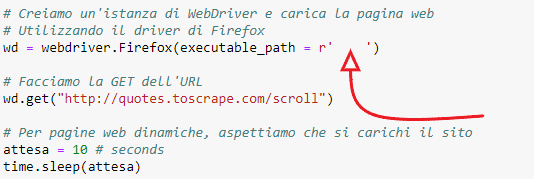
Tra i due apici, indicati dalla freccia, va inserito il percorso dell’eseguibile. Se, per esempio, volete utilizzare il driver Chrome, dovrete sostituire la dicitura Firefox con Chrome. In ogni caso, se vi doveste bloccare quando costruite un flusso di scraping con Selenium, potete consultare questo sito.
Il secondo blocco di codice apre, con il web driver istanziato in precedenza, ovvero wd, il link http://quotes.toscrape.com/scroll.
Prima di proseguire con le altre operazioni, impostiamo un tempo di attesa di 10 secondi.
Gestione dello scrolling infinito
Se aprite il link http://quotes.toscrape.com/scroll e cominciate a scorrere la pagina, noterete che possiede la funzionalità dello scrolling infinito. In pratica, ogni volta che raggiungiamo il limite inferiore della pagina verranno caricate nuove citazioni.
Per questo motivo, se vogliamo estrarre tutte le citazioni, dobbiamo scorrere la pagina fino alla fine. Il codice seguente ci permette di fare proprio questo. In modo più specifico:
- Impostiamo un tempo di attesa tra un iterazione e l’altra, per aspettare che la pagina si carichi completamente;
- Troviamo l’altezza corrente della pagina;
- Con un ciclo while, eseguiamo lo scroll della pagina fino a quando la nuova altezza della pagina è uguale a quella precedente.

Se le citazioni si trovassero in più pagine, potremmo usare del codice concettualmente simile: un cliclo while che ripete il click sul bottone pagina successiva e l’estrazione dei dati.
Output del Python tool
Con il codice seguente, vedremo come:
- Scaricare il codice sorgente della pagina;
- Chiudere il browser;
- Generare l’output dal tool Python al flusso Alteryx.
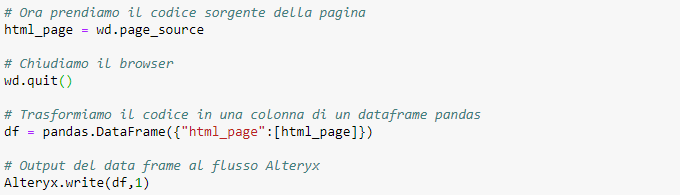
Prima di tutto, scarichiamo il codice sorgente della pagina che abbiamo aperto con il web driver wd e lo salviamo in html_page. Dopodiché, chiudiamo l’istanza del web driver.
Poi trasformiamo html_page in un data frame per generare l’output dell’ancora 1:
Infatti, per collegare il Python tool a un altro tool e far scorrere i dati lungo il flusso, è necessario utilizzare le funzioni:
Alteryx.read("nome dell'ancora di input");Alteryx.write(nome del data frame, numero dell'ancora di output).
Parsing
Ora, seguendo la tecnica dell’articolo precedente, facciamo il parsing degli elementi che ci interessano:
- Citazione;
- Autore;
- Tags.

Prima di tutto, utilizzando il trucco dell’articolo precedente, separiamo il codice in blocchi, uno per citazione:
- Con il Formula tool andiamo a sostituire alla stringa
<div class="quote">un carattere non contenuto nel documento, come per esempio ~; - Con un Text to Columns, dividiamo la colonna DownloadData in righe sul carattere scelto.
- Tramite un filtro possiamo escludere la prima parte del codice, che non contiene citazioni.
Quindi, inserendo nel flusso due RegEx tool, in modalità Parse, andiamo ad estrarre dal campo html_page le colonne:
- Citazione:
<span class="text">([^<]+)</span>; - Autore:
<small class="author">([^<]+)<.
Dopodiché, per estrarre i Tag, inseriamo un altro RegEx tool, stavolta in modalità Tokenize, e lo configuriamo come nell’immagine:
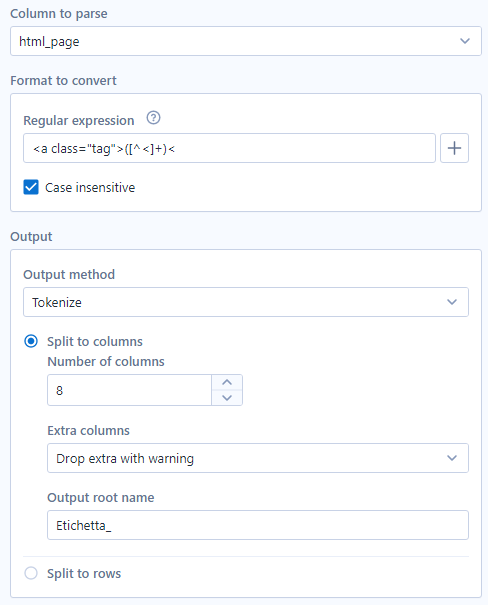
Il metodo tokenize consente di estrarre tutte le occorrenze che corrispondono alla RegEx inserita. Qui ho specificato un numero di colonne, 8, perché conoscevo già il numero massimo di tag che poteva avere una citazione. Tuttavia, è possibile anche dividere le occorrenze in righe.
Ora non rimane che salvare il risultato nel formato che preferite, con un Output tool. Questo è il risultato:

Spero che gli esempi mostrati in questa serie di articoli vi siano stato utili per comprendere come implementare un processo di web scraping con Alteryx, o perlomeno come muovere i primi passi.
Seguitemi su Twitter, LinkedIn e Tableau Public per altre novità legate a Tableau e Alteryx.
[button URL=”http://www.tableau.com/partner-trial?id=45890″]Scarica Tableau[/button] [button URL=”https://www.theinformationlab.it/newsletter-2/”]Iscriviti alla newsletter[/button]

