 Vai al contenuto
Vai al contenuto

Può capitare di dover gestire dei file csv, risultato di estrazioni da altri sistemi, come ad esempio Business Object (SAP BO), che hanno talmente tante colonne che ad un certo punto l’estrattore taglia le stringhe troppo lunghe, che vengono scritte a capo, rendendo il file inutilizzabile.
Il file csv in questione (download file) ha un formato del genere:

Come potete vedere dalla screenshot, la riga numero 4 è evidentemente la coda finale della riga precedente. Dovrebbe far parte della riga numero 3.
Ma se ci viene estratta in questo modo, sarà praticamente impossibile utilizzare il file, settando come carattere delimitatore il pipe, la riga verticale.
Vediamo insieme come sfruttare Alteryx per risolvere il problema in modo dinamico in 4 semplici step:
- Aprire il file csv senza alcun delimitatore: un’unica colonna di dati, tante righe ed eventuali titoli di colonna scritti nella prima riga
- Contare quante volte si ripete il delimitatore: per stabilire se una riga è completa oppure no
- Raggruppare le righe nel modo corretto: concatenando assieme le righe tagliate
- Rinominare le colonne in modo automatico: utilizzare la prima riga di dato per rinominare le colonne
Aprire il file CSV senza alcun delimitatore
Partiamo con un Input Tool, e andiamo a cercare il file CSV.
Configuriamo l’opzione numero 5 per non settare alcun carattere delimitatore, sostituendo la virgola con \0 (backslash zero)

E anche l’opzione numero 6 per creare un titolo di colonna fittizio, Field_1, e considerare la prima riga del csv come se contenesse dati.
Se le stringhe di testo fossero nel complesso più lunghe di 254 caratteri, mandando in esecuzione leggerai dei messaggi di warning che ti avvisano che alcune righe sono state troncate. Aumenta la lunghezza della colonna, aumentando il valore dell’opzione 7.
Se andiamo ad analizzare come sono fatte le stringhe di testo, possiamo notare come in questo caso qualsiasi stringa più lunga di 220 caratteri venga troncata a capo.
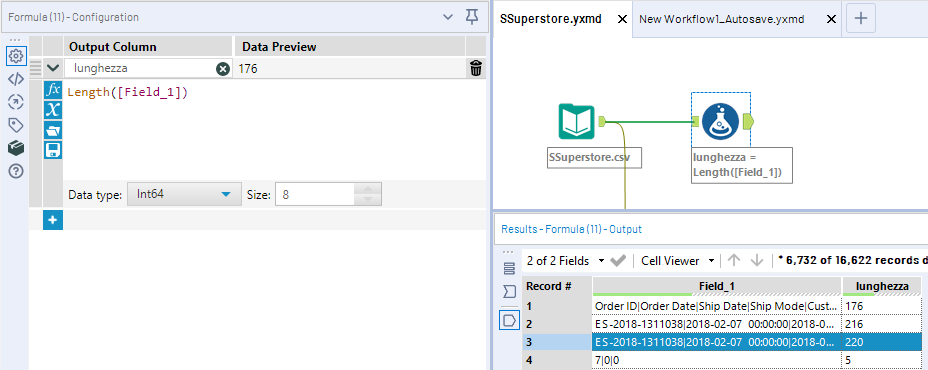
Potremmo metterci a trovare una regola logica, basata sulle lunghezze, ma sarebbe complicato.
Se la lunghezza è 220, allora concatena la stringa con la stringa che c’è nella riga successiva. E se ce ne sono due consecutive da 220, che sono proprio lunghe 220 e non hanno il pezzo mancante a capo? Andiamo a concatenare 2 righe che dovrebbero restare separate.
Stessa sorte se proviamo a ragionare con lunghezze minori di 220. Se è minore di 220 allora è un avanzo di una riga superiore. Ma in realtà non è così, perché non è un file a dimensioni fisse, una riga completa può essere lunga 176 caratteri ed essere appunto completa.
E’ più semplice contare i caratteri delimitatori. Questo csv è composto da 19 colonne. Quindi se la riga è completa, dovrò contare 18 pipe/righe verticali. Se il conteggio è inferiore, vuol dire che la riga è incompleta e dobbiamo recuperare dei pezzi dalle righe successive.
Contare quante volte si ripete il carattere delimitatore
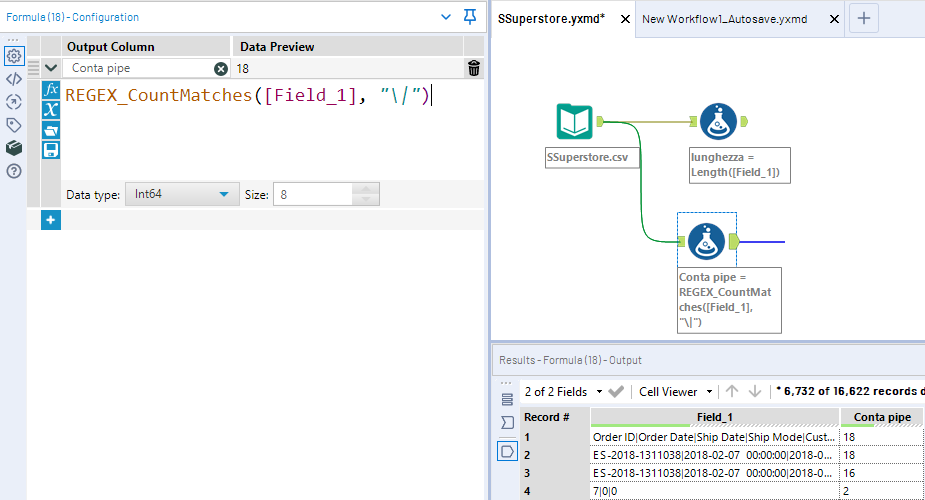
Contiamo quante occorrenze del pipe abbiamo in ogni record. Possiamo farlo grazie al Formula Tool e alla funzione REGEX_CountMatches, che conta quanti match ci sono con il pattern descritto:
REGEX_CountMatches(String, “Pattern”)
REGEX_CountMatches([Field_1], “\|”)
Conta quante volte trovi un “\|” pipe nella colonna Field_1. Il backslash va messo prima del carattere pipe semplicemente perché il pipe è un operatore regex. Se fossimo alla ricerca di virgole, punti e virgole potremmo scrivere direttamente “,” oppure “;”. Stessa cosa per il punto. Anche lui è un operatore regex e dobbiamo mettergli davanti un backslash “\.” per indicare che in questo caso lo vogliamo utilizzare come simbolo e non come operatore.
Raggruppare i dati in modo corretto
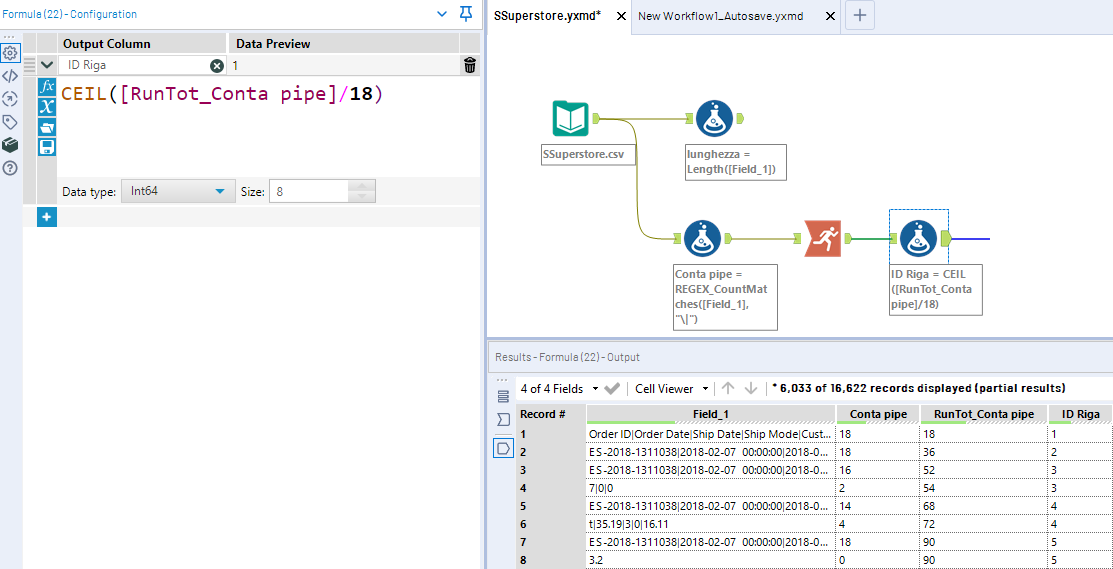
Ora supponiamo di creare una somma cumulativa del conteggio dei pipe, usando un Running Total Tool:

Se dividiamo per 18 questa somma (ossia per il numero massimo di delimitatori che mi aspetto di avere in caso di stringa completa), e ci facciamo restituire l’intero più grande, avremo che:
18 / 18 = 1 (riga numero 1)
36 / 18 = 2 (riga numero 2)
52 / 18 = 2,8 –> 3 (riga numero 3)
54 / 18 = 3 –> 3 (riga numero 3)
Siamo riusciti a raggruppare il record 3 e 4 con lo stesso ID di riga da noi calcolato.
La funzione che possiamo utilizzare per ricreare questa logica in Alteryx all’interno di un Formula Tool, si chiama CEIL e restituisce l’intero più grande o uguale al risultato. In pratica funziona come l’arrotonda per eccesso di Excel.
Ora possiamo utilizzare un Summarize Tool e concatenare tutte le righe che hanno lo stesso ID: Group by ID Riga, Concatena Field_1.
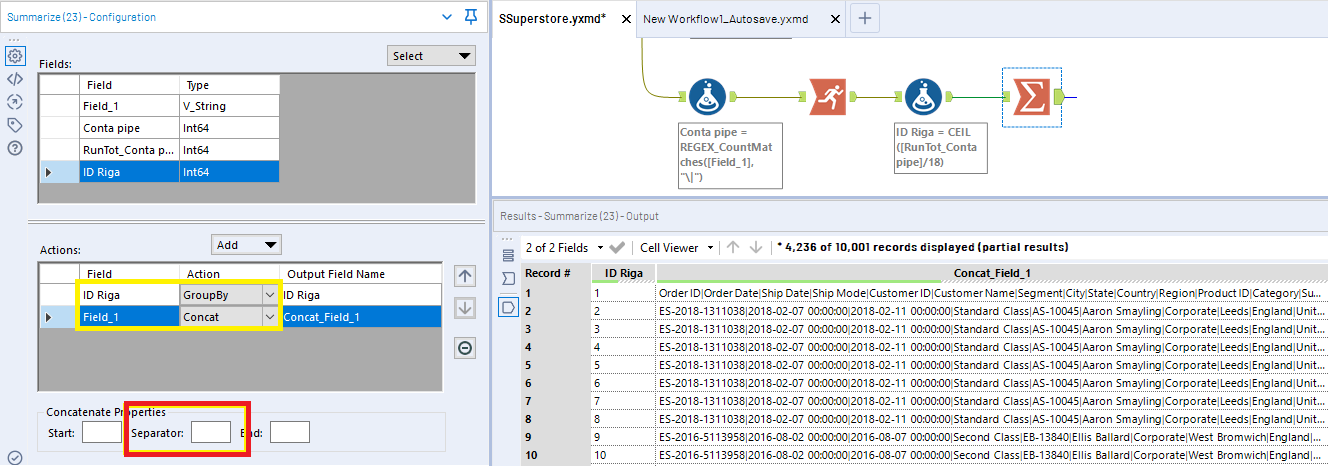
Fate attenzione al menù in basso che appare quando scegliamo l’aggregazione Concat, che sta nel sottomenù String, in quanto di default è già impostato per avere una virgola come separator. Cancelliamo tutto e concateniamo senza alcun separatore (se la riga è stata troncata, dobbiamo riattaccarla senza delimitatori).
Rinominare le colonne in modo dinamico
Ora che abbiamo ripristinato le giuste stringhe di testo, possiamo procedere al taglio delle colonne con il Text to Columns Tool, che corrisponde alla funzionalità testo in colonne di Excel.
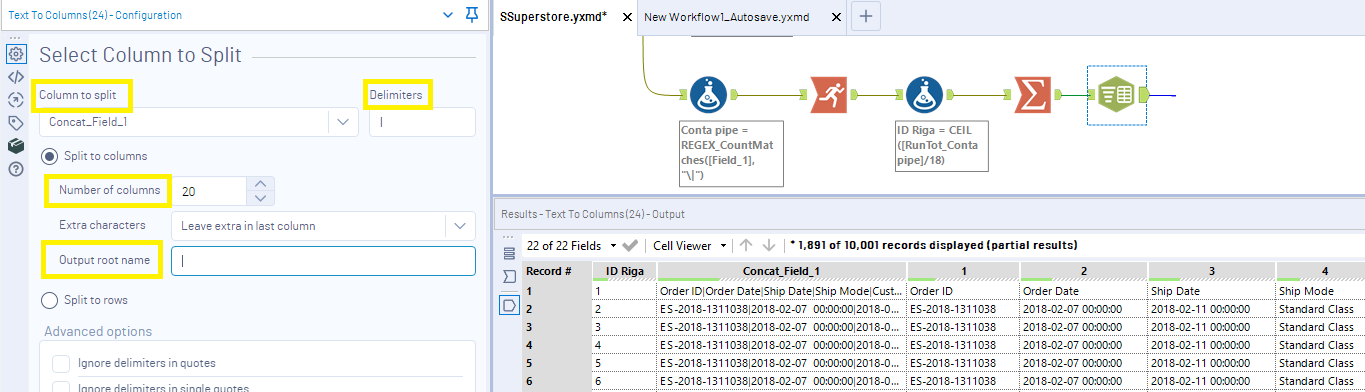
- Column to split: la colonna che vogliamo dividere, ossia Concat_Field_1
- Delimiters: il carattere delimitatore, ossia il pipe |
- Number of columns: il numero di colonne da creare, ne basterebbero 19, ma ne metto 20 per creare una colonna aggiuntiva che – se abbiamo fatto tutto bene – dovrà essere completamente piena di nulli. Possiamo usarla come controllo
- Output root name: la radice nel titolo delle nuove colonne, se lo lasciamo vuoto, verranno create delle colonna che si chiamano 1, 2, 3, 4…
Rinominare le colonne in modo automatico
Ora abbiamo la struttura della tabella colonnare e i titoli sono nella prima riga. Possiamo sfruttare il Dynamic Rename Tool, che si trova nella tab Developers, per rinominare in modo dinamico le colonne usando i dati presenti nel primo record.
Se non trovi il tool da nessuna parte, significa che devi abilitare la visualizzazione della tab Developers.
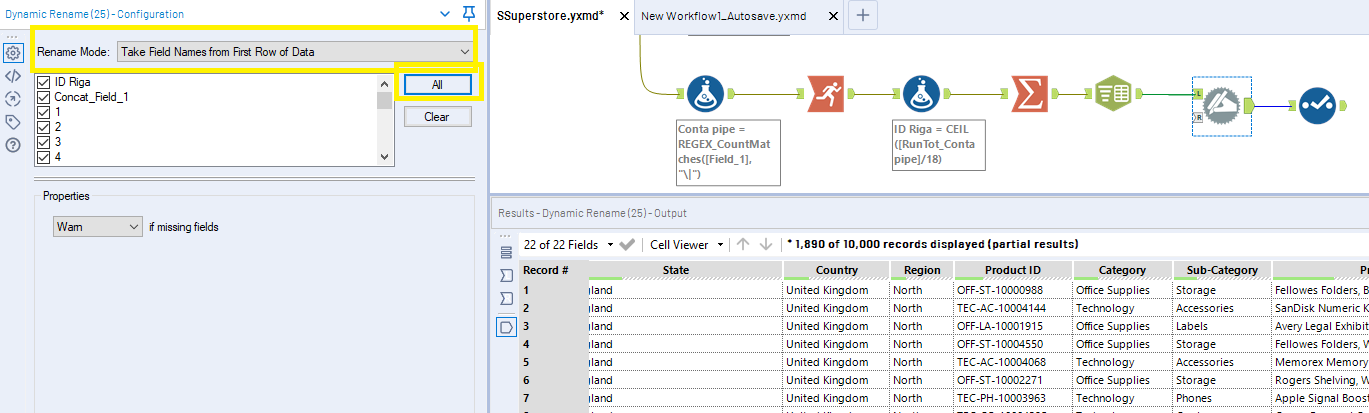
Clicca sul pulsante All per selezionare tutte le colonne e poi dal metodo di rinomina scegli Take field names from first row of data.
Poi un select per deselezionare le colonne originali ormai inutili ed eccoci al risultato finale!
La cosa interessante di questo flow è che sarà riutilizzabile all’infinito.
Se un domani dovessi avere un csv composto da 25 colonne che ha come delimitatore il meno, potrai sostuire il meno nella formula in cui adesso contiamo i pipe e nel text to column e sostituire 18 con 25 nella formula dell’ID di riga e tutto continua a funzionare.

