 Vai al contenuto
Vai al contenuto

Ciao a tutti! Oggi vi mostrerò come utilizzare in Alteryx uno dei Tool della “famiglia” predictive con un esempio pratico e comprensibile.
L’oggetto della nostra analisi saranno i club di serie A per la stagione 2012-2013. L’obiettivo di questo progetto sarà quello di analizzare e raggruppare le società di calcio partecipanti al campionato di serie A analizzando variabili gestionali ed economiche. In particolare attraverso l’utilizzo del K-Centroids Cluster Analysis Tool, andremo a confrontare il risultato della classifica finale del campionato 2012-13 con l’output del modello che costruiremo. Partendo dalla ricerca dei parametri delle variabili che andranno a formare il nostro database, raggrupperemo in n gruppi le unità statistiche attraverso misure di similarità/dissimilarità in modo da ottenere un minor numero di cluster tali che la variabilità sia minima all’interno e massima tra i gruppi stessi.
IL DATASET
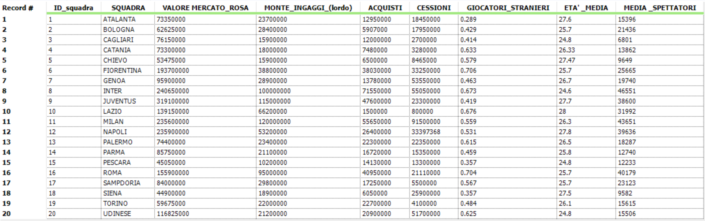
Le unità statistiche dell’analisi sono le 20 squadre che hanno partecipato al campionato di serie A 2012-13. Associate ad ogni unità ho individuato 7 variabili che descrivono il comportamento delle società in ambiti sia economici che gestionali.
Descrizione variabili:
- Valore mercato rosa (€): descrive il valore monetario della rosa composta dalla sommatoria del prezzo di mercato di ogni singolo calciatore.
- Monte ingaggi (€): descrive la spesa che ogni società sostiene nel 2012-13 per gli stipendi dei calciatori.
- Acquisti (€): individua la spesa sostenuta per l’acquisto di nuovi calciatori da inserire in rosa nel 2012-13.
- Cessioni (€): individua le entrate derivanti dalla cessione dei calciatori.
- Giocatori stranieri (%): rappresenta la presenza in squadra di giocatori provenienti da paesi esteri.
- Età media (anni): media aritmetica dell’età dei giocatori che compongono la rosa.
- Media spettatori (numero): media aritmetica della presenza di spettatori allo stadio nell’arco della stagione.
La tabella seguente riassume le variabili sopra descritte che rappresenteranno gli input del nostro modello:
STEP 1
SETTAGGIO DEL TOOL
A questo punto, passiamo ad analizzare il settaggio specifico del tool che consentirà di raggruppare le unità statistiche (Club di serie A) secondo le variabili sopra descritte.
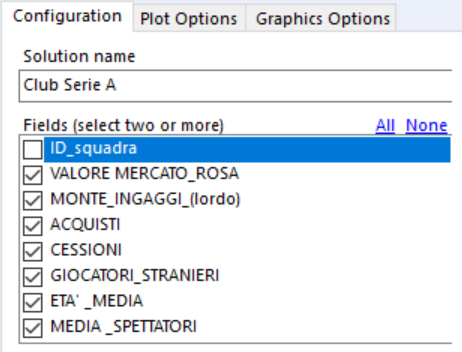
Nella prima sezione del pannello (Configuration) ci verrà chiesto di nominare il modello (Solution name) e di selezionare le variabili da inserire nel modello.
Nel nostro caso selezioneremo tutte le variabili numeriche presenti nel dataset, escludendo quindi l’ID_squadra. E fin qui tutto molto semplice…
Il prossimo step sarà quello di decidere se è il caso di standardizzare le variabili prima di darle in “pasto” al modello. Il tool a questo punto ci darà due possibilità (o metodi):
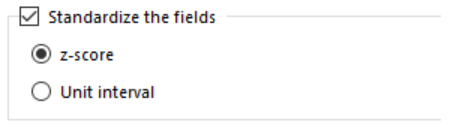
- Z-score: implica la sottrazione del valore medio per ogni campo/variabile (es. media Valore mercato rosa (€): 270.000) da ogni singolo valore appartenente ad ogni unità statistica per quel campo (es. Atalanta Valore mercato rosa (€): 73.350.000) e quindi diviso per la deviazione standard del campo stesso. Ciò si traduce in un nuovo campo che ha una media di zero e una deviazione standard di uno (nonostante il giro di parole spero sia chiaro).
- Unit Interval: implica la sottrazione del valore minimo di un campo dai valori del campo e quindi la divisione per la differenza tra il valore massimo e minimo del campo. Ciò si traduce in un nuovo campo che ha valori che vanno da zero a uno.
Le soluzioni di clustering sono molto sensibili al ridimensionamento dei dati, in particolare se un campo è su una scala molto diversa rispetto a un altro. Di conseguenza, ridimensionare i dati è qualcosa che dovrebbe essere considerato.
Nel nostro caso specifico avendo unità di misura diverse delle singole variabili decidiamo di standardizzare (quindi flaggando “Standardize the field”) secondo il metodo dello z-score (il più utilizzato).
Nella sezione “Clustering method” possiamo decidere la tipologia di metodo da utilizzare.
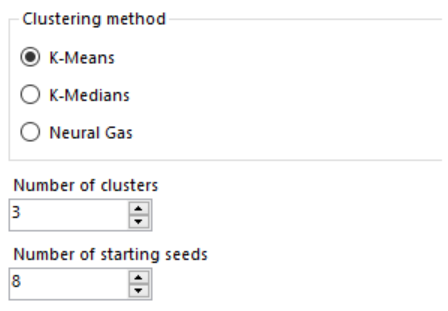
Abbiamo tre possibilità:
- K-means; metodo basato sulla suddivisione di n osservazioni in k cluster in cui ogni osservazione appartiene al cluster con la media più vicina, fungendo da prototipo del cluster.
- K-medians; una variazione di k-means clustering dove invece di calcolare la media per ogni cluster per determinare il suo centroide, si calcola invece la mediana.
- Neural Gas; è un semplice algoritmo per trovare rappresentazioni ottimali dei dati basati su vettori di elementi. Si applica quando la compressione dei dati o la quantizzazione vettoriale è un problema, ad esempio il riconoscimento vocale, l’elaborazione delle immagini o il riconoscimento dei pattern.
Nel nostro caso utilizzeremo il metodo k-means.
Ogni metodo ha la sua utilità, chiaramente ho cercato di sintetizzare la spiegazione in modo da non rendere troppo noioso il blog (…non me ne vogliano gli statistici).
Infine, essendo il metodo non gerarchico nel quale il numero dei cluster finale sarà deciso a priori avremo la possibilità di decidere in “Number of clusters” e in “Number of starting seeds” sia il numero dei gruppi che si formeranno nell’output finale, che il numero dei centroidi da cui partirà l’algoritmo (nel nostro caso 3 cluster, partendo da 8 centroidi iniziali). Nel caso abbiate perplessità sulla scelta del numero dei cluster da utilizzare nel modello, in Alteryx è disponibile un altro tool il K-Centroids Diagnostics Tool che vi darà qualche indicazione in più per effettuare una scelta ponderata.
STEP 2
ANALISI OUTPUT
Ma andiamo avanti e passiamo all’analisi dell’output del nostro tool…
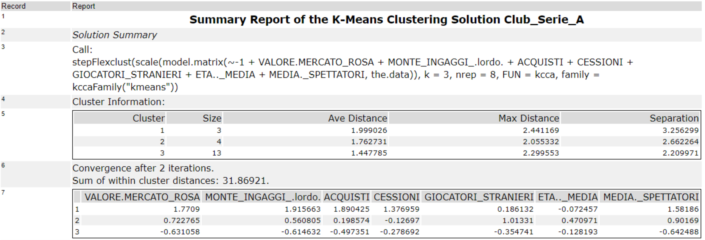
Una volta avviato il nostro flusso, la prima parte dell’output del tool fornirà tutta una serie di informazioni relative ai cluster generati, come ad esempio la grandezza (size) delle unità che li compongono; la distanza tra e intra cluster (Ave Distance, Max Sistance, Separation ecc.); il numero di iterazioni che il modello avrà effettuato e così via.
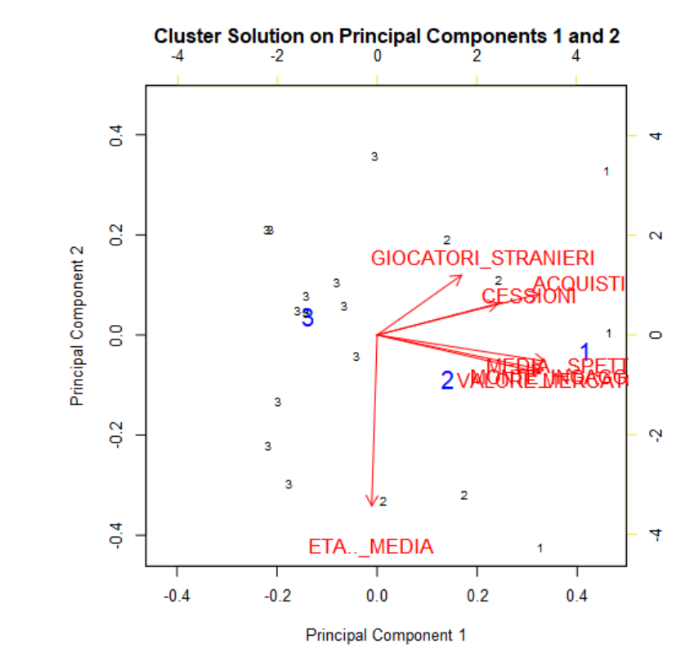
Nella seconda parte, nello specifico la sezione Plots, verrà mostrato il grafico che descrive il modello secondo le Componenti Principali (molto spesso l’analisi cluster viene affiancata dall’analisi per componenti principali e non è il nostro caso), con il posizionamento di ogni unità statistica (in nero) interno al proprio cluster con i relativi centroidi (in blu).
STEP 3
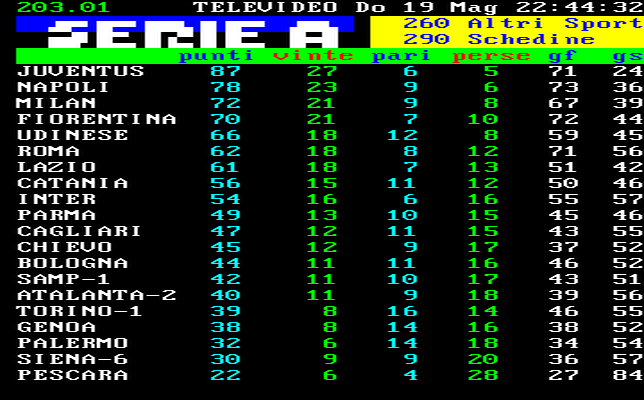
CONFRONTO CON I DATI REALI
In questa fase finale non ci rimane che assegnare le unità statistiche (i nostri club di serie A) al rispettivo cluster e confrontarle con la classifica finale, per capire effettivamente se la nostra analisi possa avere un senso.
In questo caso Alteryx ci fornisce un altro tool che ci permetterà di portare a termine l’assegnazione del club al cluster di riferimento, ovvero l’Append Cluster.
Questo tool avrà nello specifico due input (tabella iniziale e analisi cluster) e un output (la tabella finale completa di entrambe le informazioni) come mostrato nella tabella finale successiva.
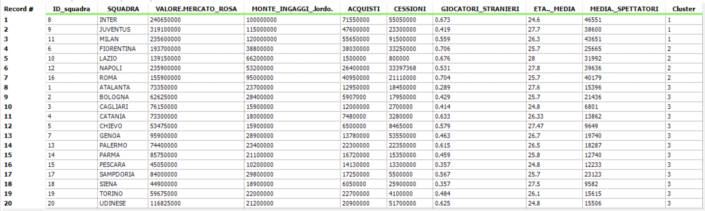
Confrontiamo questo risultato con la classifica finale del campionato di serie A stagione 2012-2013. Secondo la nostra analisi il Cluster 1 è costituito da Inter, Juventus e Milan; se consideriamo questo come il gruppo delle squadre che lottano per vincere il campionato, notiamo che rispetto alla classifica reale si differenzia solo per la presenza del Napoli. Il Cluster 2 è costituito da Fiorentina, Lazio, Napoli e Roma; anche in questo caso notiamo che “l’intruso” sarà l’Udinese che dovrebbe far parte dell’ultimo Cluster che contiene la maggior parte delle squadre della serie A. L’ultima informazione che risalta più all’occhio è la posizione dell’Inter che ha ottenuto dei risultati sportivi piuttosto negativi rispetto allo sforzo economico sostenuto dalla società.
Spero che questo esempio di analisi possa esser stato utile per comprendere l’utilizzo di uno dei tool Predictive messo a disposizione da Alteryx.
Ciao a presto…
Seguitemi anche su LinkedIn e Tableau Public.
[button URL=”http://www.tableau.com/partner-trial?id=45890″]Download Tableau[/button] [button URL=”https://www.theinformationlab.it/newsletter-2/”]Iscriviti alla newsletter[/button]

