 Vai al contenuto
Vai al contenuto

Ora che abbiamo visto cosa si intende per Data Wrangling e quali sono i termini principali utilizzati nell’ambiente di Trifacta, iniziamo a vedere:
- Come creare un nuovo flusso
- Come importare i dati in un flusso di Trifacta
- Come creare una Recipe
Per semplicità e coerenza, utilizzeremo gli stessi termini presenti sulla piattaforma di Trifacta.
Creare un flusso
Innanzitutto, un flusso è composto da tre categorie di componenti:
- Dataset: la fonte dei dati che vogliamo trasformare
- Recipe: l’insieme degli step o istruzioni necessari per definire le trasformazioni che vogliamo applicare ai nostri dati
- Output: il risultato ottenuto dopo aver applicato una Recipe ad uno o più dataset
Dall’interfaccia di Trifacta, cliccando sull’icona Flows ![]() nella barra laterale a sinistra, possiamo entrare nella pagina che raccoglie tutti i nostri flussi sviluppati sulla piattaforma. Per creare un nuovo flusso, clicchiamo in alto su Create > Create Flow.
nella barra laterale a sinistra, possiamo entrare nella pagina che raccoglie tutti i nostri flussi sviluppati sulla piattaforma. Per creare un nuovo flusso, clicchiamo in alto su Create > Create Flow.
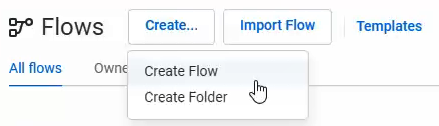
Cliccando su Untitled Flow in alto, ovvero sul nome predefinito del flusso, possiamo rinominare il flusso a nostro piacimento. E’ sempre consigliabile farlo subito, per evitare di ritrovarsi dei flussi con nomi simili nella raccolta.
L’interfaccia ci porta quindi sul Canvas del nostro flusso, dove andremo a creare e modificare i relativi componenti, sempre tenendo bene in mente che, affinché un flusso sia considerato completo, deve avere almeno un componente per categoria. Ovviamente possiamo aggiungere anche più di un componente.
Come importare i dati in Trifacta
Adesso dobbiamo identificare i dati che vogliamo trasformare. Trifacta può connettersi e importare i dati da diverse fonti, tra cui:
- File locali
- Hadoop Distributed File System (HDFS)
- Cloud Native Storage
- Database relazionali
- Data warehouse
Cliccando su Add Dataset dal nostro Canvas, possiamo selezionare i dataset da aggiungere al flusso. Qui saranno presenti anche eventuali file utilizzati in precedenza.
Andando su Import Datasets in basso a sinistra, si apre la pagina dedicata appunto al caricamento di nuovi dataset. Di default, possiamo caricarne uno nuovo dal nostro disco locale cliccando su Upload oppure importare i dati tramite i connettori predefiniti, che vengono aggiunti in base all’ambiente di Trifacta scelto durante la prima fase di registrazione alla piattaforma. Altre tipologie di connessione possono essere aggiunte cliccando su New in basso a sinistra (e da qui possiamo anche vedere quali tipologie di connettori sono disponibili).
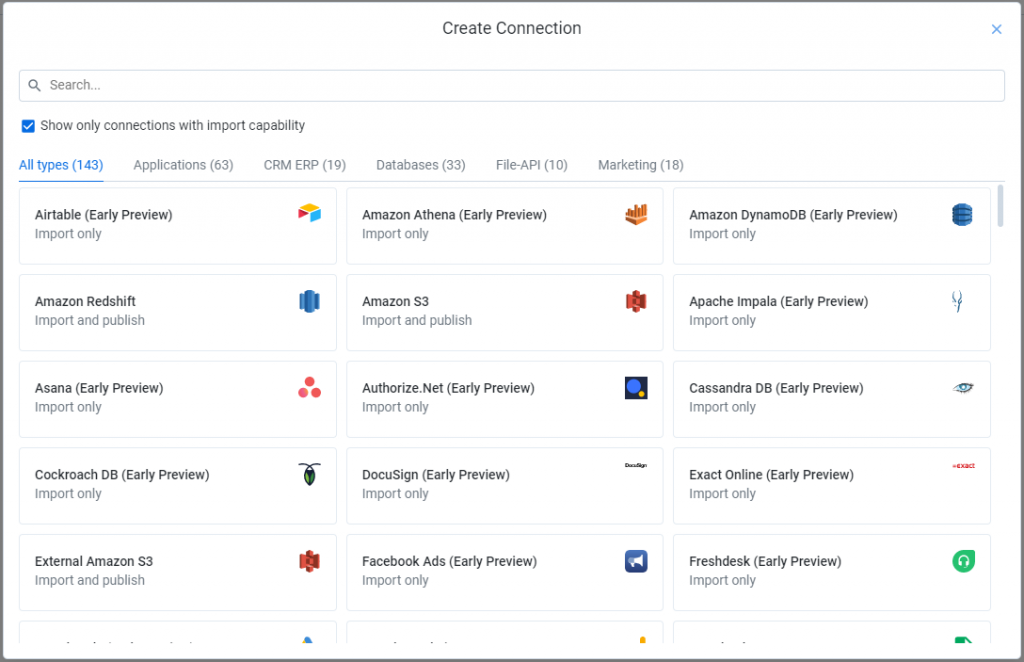
Andiamo ad esempio a importare i dati di un file salvato in locale cliccando su Upload. Le tipologie di file che possiamo caricare direttamente tramite caricamento sono le seguenti:
- CSV
- TXT
- JSON
- Avro
- Parquet
- XLS
Per caricare un file possiamo cliccare su Choose a file e selezionarlo oppure trascinarlo direttamente in questo box da una cartella aperta. In questo caso, andiamo a caricare due file CSV di esempio. Una volta completato il caricamento dei file, sulla destra abbiamo una prima anteprima dei file e la possibilità di eliminare alcuni file (cliccando sulla X affianco a ogni file). In questa fase risulteranno caricati sulla piattaforma ma non li abbiamo ancora importati nel flusso.
Possiamo eventualmente aggiungere una descrizione per ciascun file, per rendere i relativi componenti più “parlanti” all’interno del flusso.
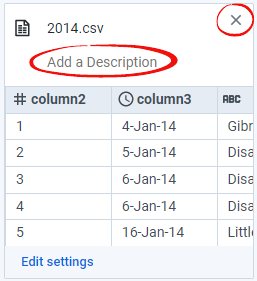
Definiti i file che vogliamo importare, clicchiamo su Import & Add to Flow in basso a destra.
Per ogni dataset importato viene creato il relativo nodo e affianco ad esso ci sarà l’icona che identifica la provenienza del dataset (ossia su che ambiente si trova). E’ importante sottolineare che il nodo in sé non rappresenta la fonte dati (in questo caso i CSV caricati), ma solo la connessione a quest’ultima.
Per intenderci, se eliminiamo un nodo dal flusso, il file risulterà ancora caricato su Trifacta e potremo riprenderlo aggiungendo e collegando ad esso un nuovo nodo. Ciò significa anche che qualsiasi trasformazione che applicheremo attraverso un componente Recipe non modificherà automaticamente i dati presenti nella fonte (il file CSV).
Creare una Recipe
In Trifacta, una Recipe contiene tutte le logiche di trasformazione dei dati presenti nei nostri dataset. Per creare una nuova Recipe, passiamo col mouse sul nodo del dataset (il nostro input) e clicchiamo sul pulsante + che appare sulla destra del nodo. Una Recipe può essere legata ad un dataset o ad un’altra Recipe e di default viene rinominata col nome del dataset cui è legata, ma possiamo personalizzare il nome facendo doppio clic sul nodo.
Ogni nodo può essere spostato all’interno del Canvas (drag & drop) in modo da organizzare al meglio il flusso. Tenendo premuto il tasto sinistro del mouse su una parte bianca del Canvas e spostando il mouse, possiamo muoverci all’interno del flusso.
Cliccando su un nodo, ci appare sulla destra una barra attraverso la quale aggiungere delle azioni e ottenere ulteriori informazioni. Ad esempio, cliccando sul nodo del dataset, la barra laterale ci mostra un’anteprima dei dati; cliccando su un nodo Recipe abbiamo un’anteprima delle trasformazioni applicate (nella sezione Recipe) e dei risultati di queste (nella sezione Data).
Dal nodo Recipe, cliccando su Edit Recipe a destra entriamo nella cosiddetta Transformer View, una pagina dedicata alle trasformazioni presenti in questo nodo. Cliccando su una delle colonne, a destra avremo una prima analisi dei valori in essa contenuti che ci da alcune informazioni, tra cui ad esempio:
- Quality: se i valori della colonna sono validi o presentano delle incongruenze/valori mancanti;
- Unique Values: quante volte si ripetono i singoli valori della colonna;
- Distribution (per variabili numeriche/date): come sono distribuiti i valori;
- Patterns (per variabili alfanumeriche): che tipo di schema seguono i valori (in base alle regole delle espressioni regolari, RegEx)
Quando selezioniamo una colonna, Trifacta ci suggerirà sempre nella barra laterale eventuali step da applicare alla colonna selezionata e una volta definiti e aggiunti gli step di trasformazione ai nostri dati, abbiamo di fatti creato una Recipe! Per tornare al flusso principale e uscire dalla Transformer View, clicchiamo in alto a sinistra sul nome del flusso (appena sopra il nome della Recipe).
Nel prossimo articolo andremo ad esplorare insieme le trasformazioni che si possono applicare in un flusso di Trifacta!
Per ulteriori domande su Trifacta vi invitiamo a contattarci all’indirizzo: info@theinformationlab.it Speriamo che questo articolo vi abbia incuriosito e che continuiate a seguire il nostro blog. Alla prossima!

