Vai al contenuto
Vai al contenuto

Come consulenti di The Information Lab Italy ci siamo fino ad ora concentrati prevalentemente su Alteryx e Tableau – strumenti utilizzati rispettivamente per la trasformazione e la visualizzazione dei dati.
Con la recente aggiunta di Snowflake siamo ora in grado di completare la nostra offerta a 360 gradi (per approfondire clicca QUI). In questo articolo verranno quindi condivise alcune riflessioni su come ottimizzare i costi di Snowflake partendo da Alteryx e Tableau.
Come funziona Snowflake e la sua struttura di costi
Quando parliamo di come possiamo ottimizzare i costi di Snowflake dovremmo prima essere a conoscenza di come funziona Snowflake e di come vengono addebitati i costi agli utenti.
Snowflake è un cloud data warehouse, offerto come Software-as-as-Service (SaaS).
Tradizionalmente i database hanno seguito un’architettura shared-disk o shared-nothing. Entrambi presentano vantaggi e svantaggi, ma il punto chiave è che Snowflake prende elementi di ogni architettura: il risultato che si ottiene è quindi un modello ibrido.

L’architettura Snowflake consiste infatti di tre layers:
- Storage
- Query Processing
- Cloud Services
Siamo quindi in presenza di un data repository centrale che è accessibile da tutti i nodi di calcolo (come nell’architettura shared-disk), allo stesso tempo però quando Snowflake esegue una query I cluster di calcolo lavorano in parallelo memorizzando una parte di dati localmente (come nell’architettura shared-nothing).
Quando andiamo ad analizzare la struttura di costi di Snowflake dobbiamo prendere in considerazione solo i layer di Storage e di Query Processing.
In termini di Storage, il concetto è piuttosto semplice: più dati si memorizzano, più costi vengono addebitati. Per quanto riguarda invece il Query Processing, entra in gioco l’architettura unica di Snowflake ed è quindi opportuno avere una comprensione di base per per capire come vengono addebitati i costi e come possiamo ottimizzarli.
Una soluzione basata sul cloud e serverless
Prima dell’avvento di soluzioni di datawarehouse come Snowflake, i database tradizionali richiedevano una hardware fisico. Solitamente le aziende dovevano decidere quanta potenza di calcolo era necessaria e pagare per un numero fisso di server.
Non di rado le aziende superavano il budget per i server nel caso in cui ci fossero stati picchi di traffico che avrebbero portato a tempo di inattività per i server – comportando quindi costi più alti.
La grande differenza di Snowflake consiste quindi nell’essere serverless: ciò significa che un’azienda non ha più bisogno né di acquistare un hardware fisico, né di installare alcun tipo di software. Snowflake è infatti interamente accessibile attraverso il browser.
Il serverless computing permette di distribuire i server dal cloud (off-premises) in modo flessibile. Non è più necessario fornire un limite massimo o minimo di potenza di calcolo: quando la domanda di calcolo sale, allora Snowflake può scalare e fornire più risorse computazionali (scaling up), viceversa quando la domanda scende si ridimensiona (scaling down).
Snowflake addebita quindi i costi ai suoi utenti in base all’uso dei cluster di calcolo utilizzati per eseguire le queries, caricare dati ed eseguire operazioni DML (Data Manipulation Language). Queste spese sono misurate dall’uso di crediti Snowflake. Questi crediti sono usati dai virtual warehouses – che sono essenzialmente cluster di calcolo usati per eseguire le operazioni descritte sopra.
I crediti vengono utilizzati solo quando i warehouses sono in funzione, se non sono richiesti per alcun processo questi andranno in uno stato di sospensione (auto-suspend mode) e non verranno addebitati crediti.
Ora che ne abbiamo compreso la struttura ci chiediamo: come possiamo ottimizzare i costi di Snowflake?
Alteryx
Non avere paura del pulsante di esecuzione!
Nel layer di calcolo di Snowflake troverai la cache dei risultati. Questa contiene i risultati di tutte le query eseguite nelle ultime 24 ore, che sono disponibili per ogni virtual warehouse. Pertanto, se ti trovi nelle prime fasi di sviluppo di un flusso di lavoro e temi di aver premuto il pulsante di esecuzione numerose volte e aver consumato potenza di calcolo, non è questo il caso. Snowflake infatti fornirà i risultati della cache dei risultati, senza addebitare crediti. Naturalmente se stai invece cambiando la query o i risultati alla base cambiano allora questo processo comporterà dei costi a livello di potenza di calcolo alla prima esecuzione.
Crea un file yxdb per lo sviluppo
Una volta che sei soddisfatto della tua query e sai che stai estraendo i dati corretti, considera la possibilità di creare un file yxdb da memorizzare localmente sulla tua macchina. Questo file può essere usato come input per il tuo flusso di lavoro Alteryx. Naturalmente, i flussi di lavoro possono essere sviluppati in più giorni o settimane, quindi la cache dei risultati di 24 ore verrà cancellata. Utilizzando però un “estratto dati” yxdb ti permetterà di non utilizzare i crediti di Snowflake per estrarre lo stesso dataset (nella fase di sviluppo infatti non deve essere necessariamente sempre aggiornato).
Utilizza SQL
Ci sono alcuni tools su Alteryx che permettono di usare SQL: pensiamo ad esempio all’Input Data, Output Data o al Connect In-DB. Quando si importano i dati infatti è consigliabile in questo caso utilizzare le clausole GROUP BY, WHERE e LIMIT per importare solo i dati necessari alla granularità richiesta.
Queste operazioni possono essere eseguite anche in seguito nel flusso di lavoro, tuttavia limitando la quantità di dati nell’SQL personalizzato si riduce di conseguenza anche l’ammontare della quantità di calcolo richiesta per importare l’intero dataset.
Seleziona l’opzione Record Limit
Più dati estrarrai dal database, più potenza di calcolo userai. Pertanto, quando svilupperai un flusso di lavoro, probabilmente non avrai bisogno di tutti i dati, ma solamente di un campione. L’opzione Record Limit si può paragonare all’uso di LIMIT come discusso sopra, ma si tratta di una soluzione che non richiede codice. È importante inoltre non confondere il Record Limit con lo strumento Sample Tool, in cui i dati sarebbero comunque portati avanti nel flusso e campionati in seguito. Ricordati però di cambiare le impostazioni del Record Limit quando sei pronto per la produzione!

Think COPY TO, non INSERT TO
Quando si scrivono dati in un database Snowflake, abbiamo la possibilità di scegliere tra INSERT e COPY. INSERT scriverà i dati nel database un record alla volta, mentre COPY farà uso del bulk loader di Snowflake, tramite cui i dati vengono copiati in batches. Quando si usa COPY non solo le prestazioni sono migliori, ma il processo è anche più veloce, e di conseguenza il server funziona per meno tempo e ciò comporta meno costi.
Come si riflette tutto questo su Alteryx? Nel tuo flusso di lavoro, quando usi lo strumento di input dei dati vedrai due opzioni, Bulk e ODBC. L’opzione Bulk utilizzerà il processo COPY, mentre ODBC l’INSERT.
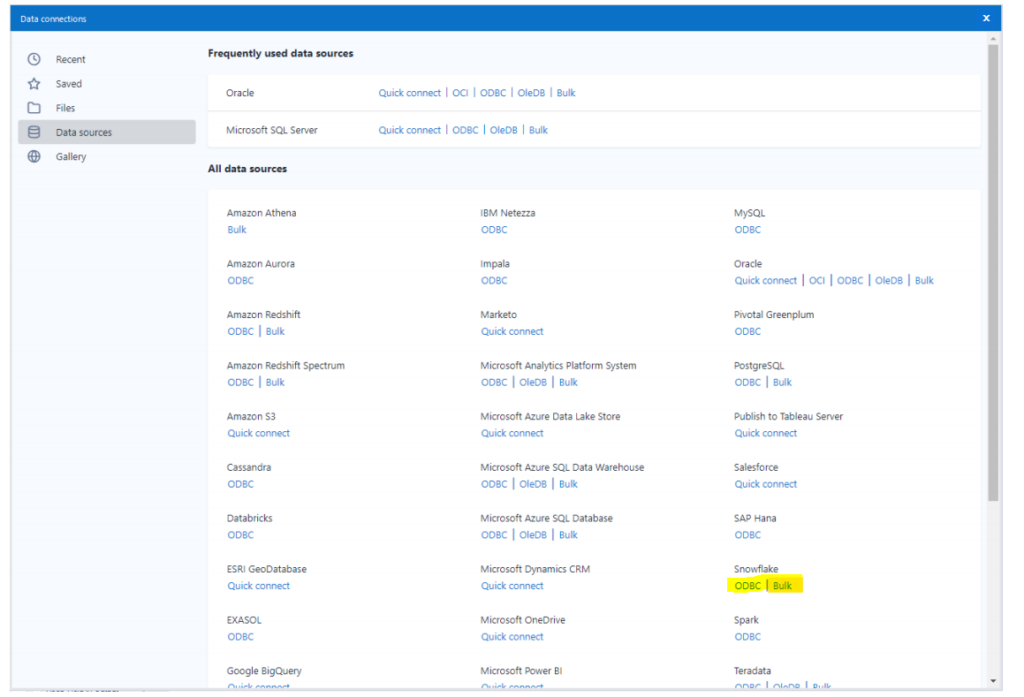
Puoi approfondire ulteriormente le potenzialità di Alteryx e Snowflake e le best practices.
Tableau
Usa gli extracts
L’uso degli extract è fortemente consigliato quando si lavora con Snowflake: se infatti si utilizza la connessione Live, ogni volta che un utente cambia un parametro o un filtro il database viene interrogato. Nel momento in cui ciò avviene, il warehouse non esce dalla modalità auto-suspend ed entra nella modalità running, inviando il risultato. Si utilizza così ogni volta la potenza di calcolo e crediti Snowflake.
Utilizza i refresh incrementali
Quando devi aggiornare i tuoi extract, considera l’utilizzo di refresh incrementali. Il motivo è ancora una volta quello di limitare le risorse computazionali richieste. Un aggiornamento incrementale porterà solo i nuovi dati assenti nel precedente dataset – in questa operazione viene utilizzata la funzione di timestamp per controllare la data ultima dei dati più recenti. Nel caso invece di un aggiornamento completo, andremmo a chiedere al nostro database di importare nuovamente ogni singolo record. Si può facilmente comprendere quindi come un aggiornamento incrementale comporterà un consumo inferiore di crediti Snowflake.
Per essere sicuri di non perdere i dati memorizzati in Snowflake, si consiglia pertanto di procedere ad un aggiornamento completo solamente ad una frequenza ricorrente appropriata.
Nascondi i campi inutilizzati quando crei un estratto
Possiamo farlo manualmente noi stessi nella scheda dell’origine dati in Tableau o quando creiamo l’estratto (vedi screenshot sotto). Una volta creato il nostro lavoro all’interno di Tableau, avremo con molta probabilità moti campi non utilizzati. Se li includiamo nei nostri estratti stiamo essenzialmente chiedendo a Snowflake di riportare dei dati che non ci servono. Considera quindi la possibilità di nascondere questi campi: in questo modo si ridurrà naturalmente il carico sul server e la potenza di calcolo richiesta.

Crea dashboard su Tableau per monitorare l’utilizzo di Snowflake
Se vuoi davvero capire l’impatto del tuo lavoro Tableau sul database Snowflake, allora è preferibile creare una dashboard per monitorare dove si concentra il carico di lavoro e in che modo potresti renderlo più efficiente. Tableau ha costruito infatti una suite di dashboard che ti permettono di connetterti direttamente al tuo account Snowflake e avere una visione dell’utilizzo della piattaforma. Le dashboard ti permettono di controllare quali warehouse stanno richiedendo più crediti e quale arco temporale di tempo, l’uso del singolo utente e il tempo trascorso per warehouse.
Clicca su questo link per saperne di più.
In sintesi
Siamo certi che Snowflake rappresenti un’ottima soluzione per molti clienti. Ora che abbiamo capito come ottimizzare i costi di Snowflake, resta solo da valutare come possiamo utilizzare il nostro arsenale ELT per ottimizzare le nostre prestazioni. In questo post ci siamo concentrati su Tableau e Alteryx, ma Snowflake si adatta perfettamente anche ad altri prodotti di analisi e visualizzazione dati.
Per ulteriori domande su Snowflake vi invitamo a contattarci all’indirizzo: info@theinformationlab.it
Speriamo che questo articolo vi abbia incuriosito e che continuiate a seguire il nostro blog.
Vi diamo appuntamento alla settimana prossima con alcuni consigli su come preparare correttamente i dati con Snowflake!
Alla prossima! ❄️