Vai al contenuto
Vai al contenuto

Al giorno d’oggi i dati sono fondamentali per tutti i processi decisionali all’interno di un’azienda. La tecnica del web scraping ci consente di estrarre i dati e le informazioni che ci interessano da uno o più siti web, per poi strutturarli, pulirli e immagazzinarli. Il tutto in maniera automatica.
Gli utilizzi del web scraping sono molteplici. Alcuni di questi sono:
- Monitoraggio dei prezzi della concorrenza;
- Analisi del sentiment dei consumatori;
- Estrazione dei punti chiave delle notizie più recenti;
- Supplemento di dati per analisi in tempo reale e analisi predittive in vari ambiti;
- Creazione di contenuti data-driven in ambito marketing;
- Generazione di lead a costi più contenuti.
In più, questa tecnica è utilizzata anche nel mondo accademico, da data journalist e dalle organizzazioni non-profit.
In questo e nel prossimo articolo di questa serie illustrerò, tramite un paio di esempi pratici, come è possibile fare scraping con Alteryx. Oggi vedremo come strutturare un flusso che funzioni con i siti web generati lato server. La prossima volta, invece, vedremo come farlo per quelli generati lato client.
Cos’è il web scraping?
Il Web Scraping (o Data Scraping) è una potente tecnologia informatica che permette di estrarre i dati dai siti web e di convertirli rapidamente in informazioni di valore.
Il processo di web data extraction prevede la scrittura di script relativi a visite di pagine web, richieste e contenuti, memorizzando gli insight acquisiti dove desiderato.
Questo si traduce nell’automazione di attività manuali ripetitive, come l’inserimento di ordini nei siti web di e-commerce o la conduzione di ricerche di mercato per la raccolta di informazioni sui prodotti della concorrenza.
Le aziende possono utilizzare i dati raccolti per il confronto dei prezzi, l’analisi del comportamento dei clienti, il monitoraggio delle tendenze online e persino l’esecuzione di analisi di marketing back-end a scopo decisionale. Il Web Scraping consente, quindi, alle aziende di costruire strategie più intelligenti e allineate alle attuali tendenze del settore.
Esempi di web scraping
Il Web Scraping sta diventando sempre più popolare nel mondo tecnologico di oggi.
Alcuni esempi comuni dell’impiego di questa tecnologia data scraping sono:
- I motori di ricerca, come Google, che monitorano milioni di pagine web per raccogliere parole, frasi, immagini, video e tutte le informazioni utili per fornire agli utenti risultati più completi e accurati.
- Gli strumenti di comparazione dei prezzi che aiutano gli utenti a trovare le migliori offerte su determinati prodotti o servizi.
- Il monitoraggio degli annunci di lavoro da più siti web contemporaneamente.
- La raccolta di indirizzi e-mail per scopi di marketing.
Quali tool utilizzare per il web scraping
I tool necessari sono:
- Alteryx Designer (se non l’avete già fatto, potete scaricare la versione trial da questo link);
- Gli strumenti per sviluppatori del vostro browser.
Inoltre, se non avete familiarità con le RegEx, vi consiglio di sfruttare un ambiente per testarne il funzionamento, come per esempio https://regexr.com/.
Il Web Scraping è legale?
La legalità dello Scraping dipende dal modo in cui viene effettuato e da quali informazioni vengono raccolte.
In generale, è legale se non comporta una violazione del copyright o l’accesso a informazioni private come password o dati finanziari.
Tuttavia, alcune aziende possono essere protettive nei confronti dei propri dati e tentare di bloccare gli scrapers. In questo caso, è importante leggere i termini di servizio di ciascun sito web da cui si effettua lo Scraping per determinare se questo è consentito o meno.
Inoltre, è importante utilizzare strumenti di anonimizzazione per garantire la privacy degli utenti di cui si raccolgono i dati.
Prima di procedere con lo scraping, è buona norma consultare alcuni documenti: le Condizioni di utilizzo, la Privacy degli utenti e il file robots.txt del sito web.
I primi due sono contratti vincolanti, in quanto applicazione diretta di normative nazionali, europee (come il GDPR) o internazionali.
Il file robots.txt è creato dal proprietario del sito per specificare su quali pagine non vuole che si faccia scraping: è consultabile alla pagina [nome del dominio del sito]/robots.txt. Per esempio, per The Information Lab Italia si trova all’indirizzo https://www.theinformationlab.it/robots.txt. Per interpretarne il contenuto potete riferirvi a questa guida.
Come fare web scraping: gli step per l’estrazione dei dati
Il flusso Alteryx che creeremo avrà lo scopo di:
- Scaricare una o più pagine web;
- Effettuare il parsing dell’HTML grazie ai pattern trovati nel codice;
- Collezionare i dati estratti in un formato strutturato.

Analisi del codice della pagina
Il sito dal quale andremo a estrarre informazioni è un portale fittizio di e-commerce creato appositamente per fare pratica con lo scraping:
http://books.toscrape.com/
Da questo sito vogliamo estrarre tutte le informazioni relative ai libri: titolo, prezzo, disponibilità, valutazione degli utenti e – perché no? – anche l’immagine di copertina.
La prima cosa da fare è analizzare la struttura della pagina web. Quindi aprite il vostro browser preferito, navigate alla pagina indicata e attivate gli strumenti per sviluppatori. Potete raggiungerli tramite il menu delle impostazioni o con la scorciatoia da tastiera Ctrl + Maiusc + I.
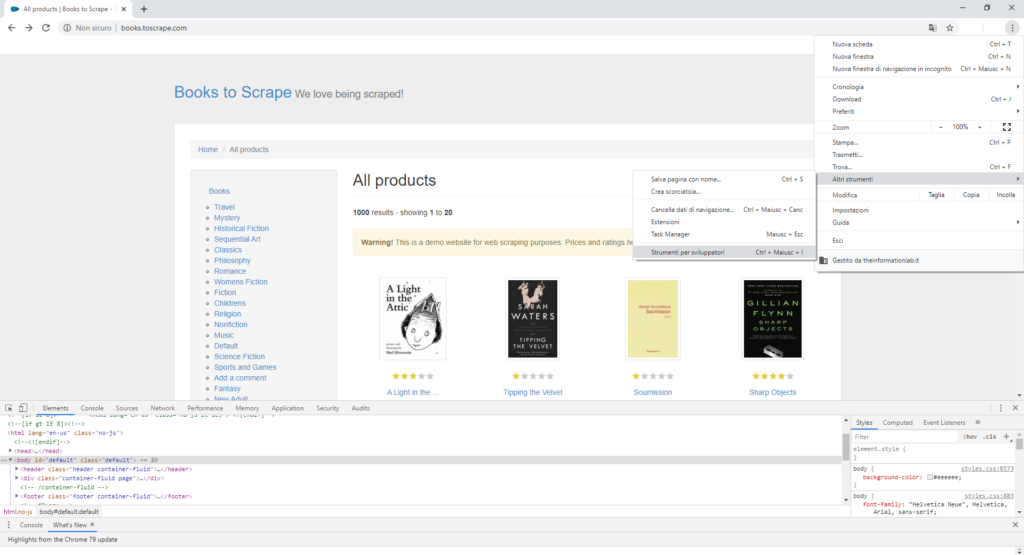
Quello che vedete nella finestra degli strumenti per sviluppatori è il codice che compone la pagina web. Per puntare direttamente alla porzione di codice che ci interessa basta:
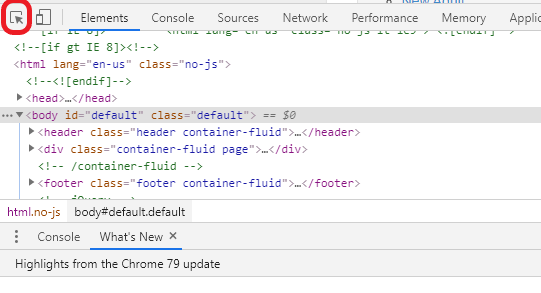
- Cliccare sulla freccia in alto a sinistra nella finestra degli strumenti per sviluppatori;
- Cliccare sul contenuto della pagina che desideriamo estrarre.
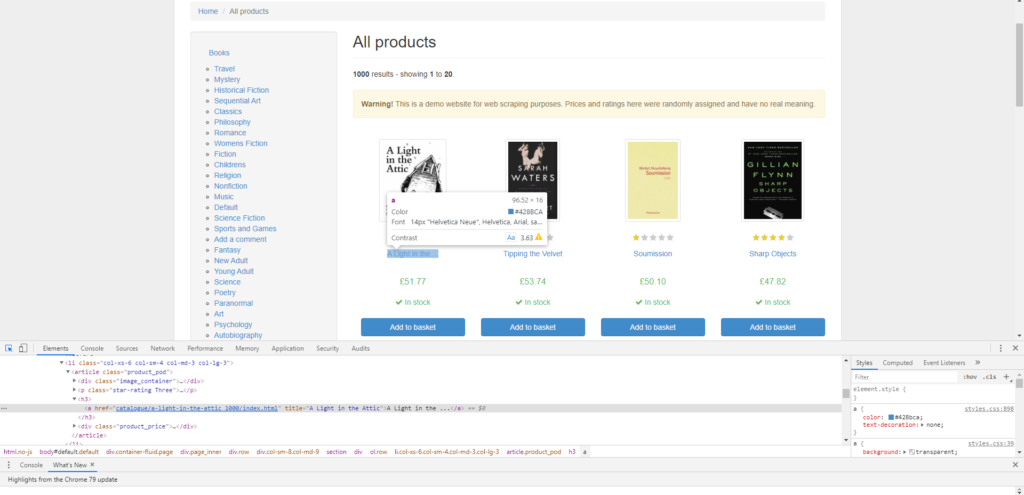
Il titolo dei libri è racchiuso in questo codice: title="A Light in the Attic". Ora proviamo a estrarre il titolo di tutti i libri visualizzati nella pagina!
Download della pagina
Prima di tutto apriamo Alteryx Designer. Dopodiché trasciniamo il tool Text Input – lo trovate nella tab In/Out – sull’area di lavoro e incolliamo il link della pagina (http://books.toscrape.com/), rinominando la colonna Link.
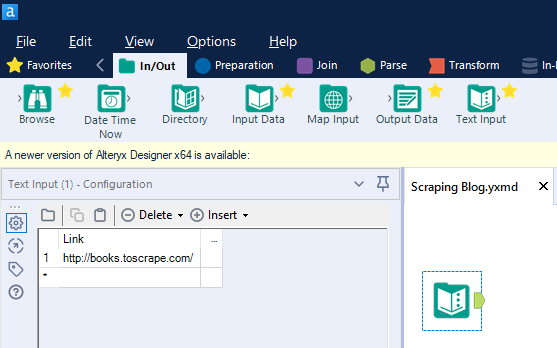
Ora trasciniamo il Download tool – lo trovate nella tab Developer – sull’area di lavoro, collegandolo al tool precedente, e lo configuriamo come nell’immagine.
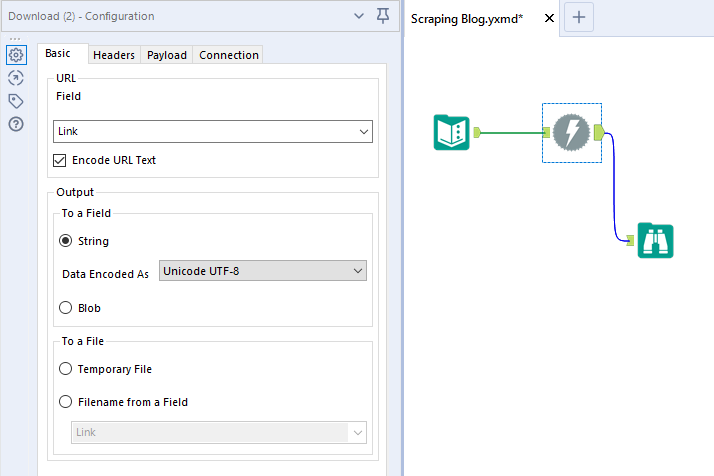
Mandiamo in esecuzione il flusso e controlliamo la finestra dei risultati.
Il download tool ha creato due nuove colonne:
- Download Data, che contiene il codice HTML della pagina da cui a breve andremo ad estrarre le informazioni che ci interessano;
- Download Headers contiene la risposta del server: se riporta la dicitura
HTTP/1.1 200 OKallora il download è andato a buon fine.
Parsing: parte I
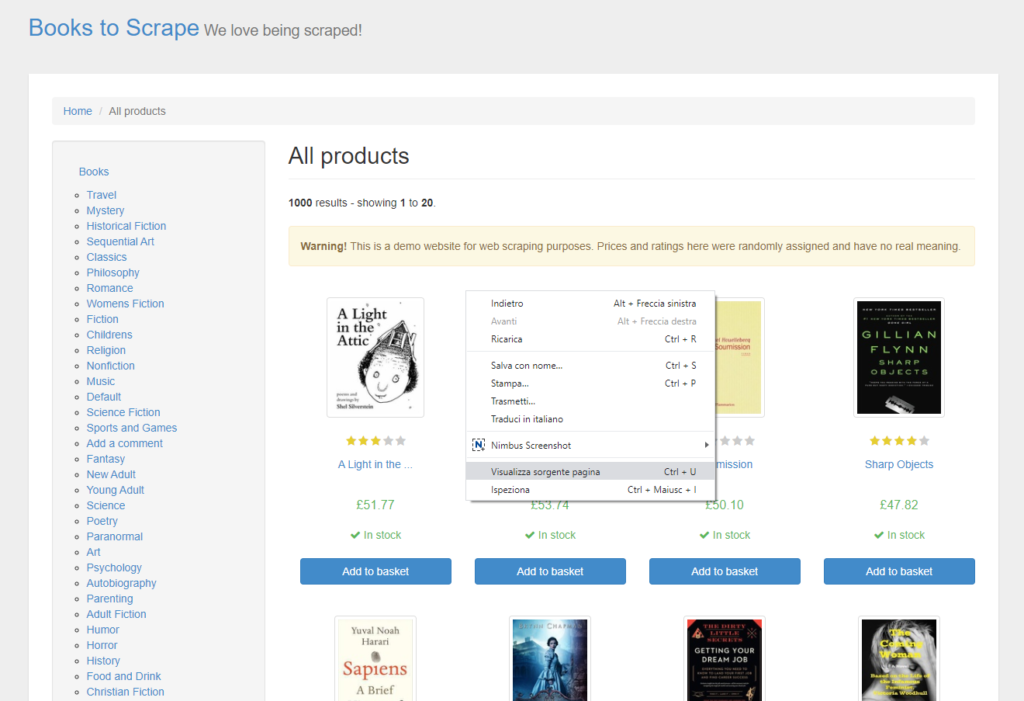
A questo punto apriamo il codice sorgente di tutta la pagina (clicca con il tasto destro del mouse su un punto qualsiasi della pagina e seleziona “Visualizza sorgente pagina”) e cerchiamo un pattern che ci consenta di spezzare l’HTML, ottenendo una porzione per libro.
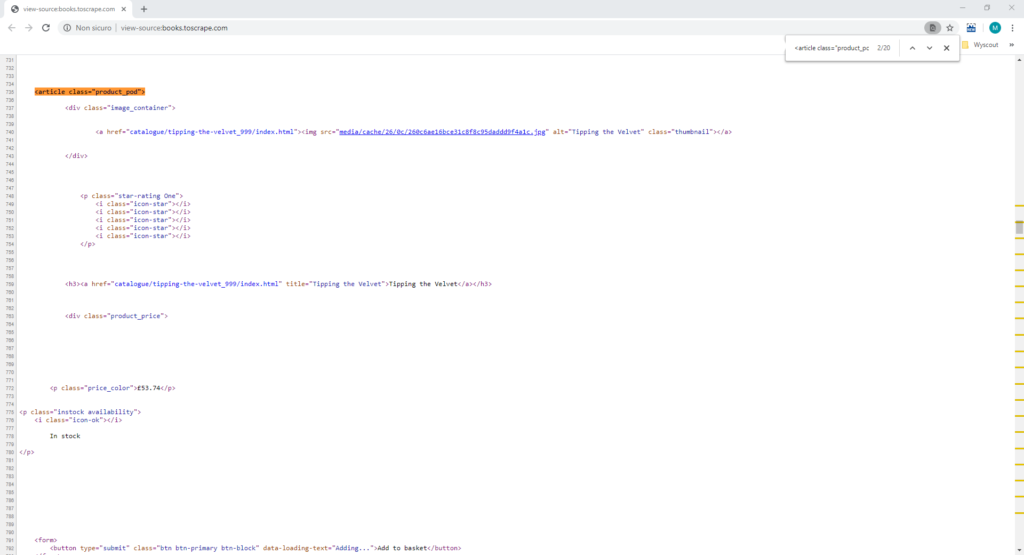
Il pattern <article class="product_pod"> sembra fare al caso nostro. Infatti è la prima riga di ogni blocco di codice – articolo. In più, se cerchiamo questa stringa nel codice sorgente troviamo 20 risultati: esattamente il numero di articoli presenti nella pagina!
Ora che abbiamo trovato il pattern, suddividiamo il codice. Un trucchetto molto semplice permette di farlo in tre semplici passaggi:
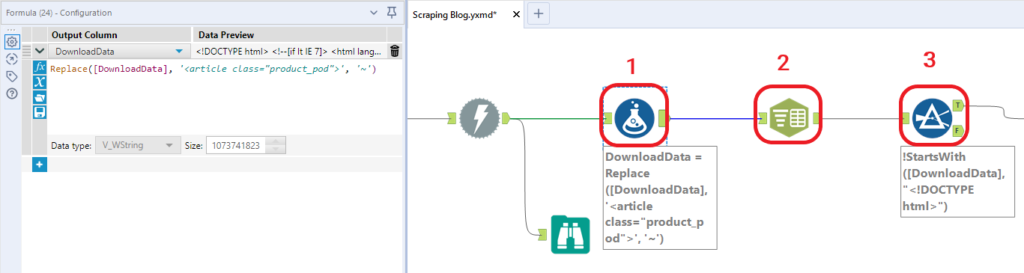
- Con il Formula tool andiamo a sostituire alla stringa
<article class="product_pod">un carattere non contenuto nel documento, come per esempio ~; - Utilizzando un Text to Columns, dividiamo la colonna DownloadData in righe sul carattere scelto.
- Con un filtro possiamo escludere la prima parte del codice, che non contiene articoli.
Parsing: parte II
Ora che abbiamo una riga per libro, possiamo cominciare ad estrarre le informazioni che ci interessano. Per farlo utilizzeremo le RegEx (Regular Expression), ovvero sequenze di simboli che identificano un insieme di stringhe. Per saperne di più vi consiglio di consultare la nostra serie di articoli a riguardo:
Spesso, soprattutto se si è alle prime armi, con le RegEx si procede per tentativi. Per questo motivo vi consiglio di sfruttare la funzionalità cache and run in corrispondenza del Download tool: Alteryx salverà nella cache tutti i dati scaricati, accorciando i tempi di esecuzione.
Ora, come facciamo ad estrarre i titoli dei libri? Per prima cosa, torniamo al codice. La parte che ci interessa è compresa nella stringa title="A Light in the Attic" per il primo libro, title="Tipping the Velvet" per il secondo e così via. Avete trovato il pattern?
La prima parte è sempre la stessa: title=. Dopodiché, il titolo è racchiuso dai doppi apici: "Titolo". In pratica, vogliamo ottenere la porzione di testo che viene dopo title=" e che contiene uno o più caratteri che sono diversi da ".
Allora trasciniamo il tool RegEx – dalla tab Parse – e lo colleghiamo al tool precedente. A questo punto:
- Selezioniamo la colonna sulla quale effettuare il parsing, ovvero DownloadData;
- Aiutandoci con il cheat sheet che troviamo all’interno del tool stesso, componiamo la nostra RegEx;
- Selezioniamo il metodo adeguato, in questo caso Parse;
- Definiamo il nome e il formato della colonna di output.
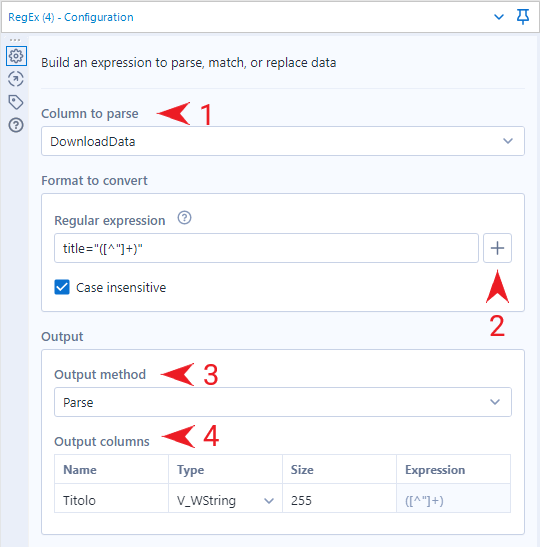
La RegEx che ho utilizzato io è title="([^"]+)":
- Cerca una stringa :
(); - Di uno o più caratteri:
+; - Formata da qualsiasi carattere tranne “:
[^"]; - Racchiusa dalla stringa
title="e".
Una logica simile si può applicare anche per comporre le espressioni regolari adatte ad estrarre le altre informazioni:
- Valutazione:
class="star-rating (\w+)"; - Prezzo:
class="price_color">([^<]+)<; - Disponibilità:
<p class="instock availability">\W*<i class="icon-ok"></i>([^]+)<; - Link Immagine:
<img src="([^"]+)".
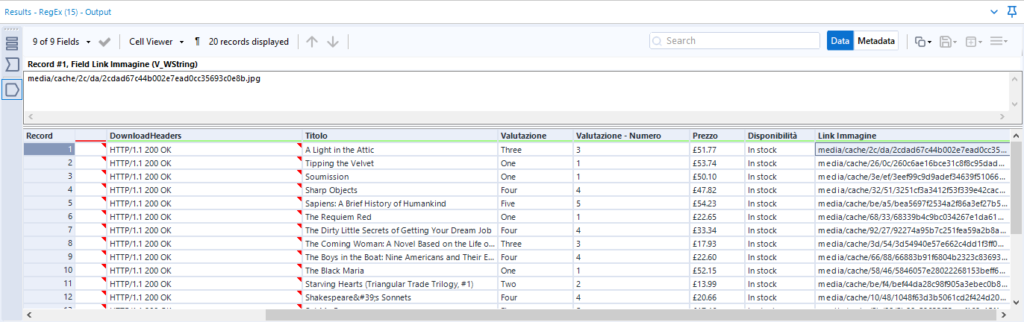
Il risultato è il seguente:
Ora non rimane che salvare il risultato nel formato che preferite, con un Output tool.
Download delle immagini di copertina
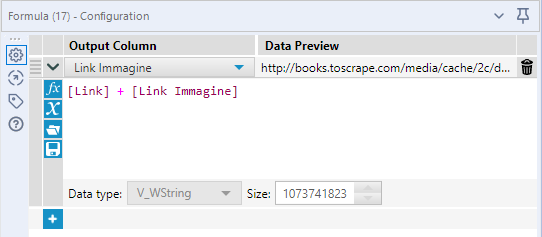
Come vedete nell’immagine precedente, i link delle immagini non sono path assoluti, ma relativi. Allora, con il tool Formula, concateniamo i link delle immagini che abbiamo ricavato con la stringa del nome del dominio del sito:
A questo punto abbiamo tutto il necessario per procedere con il download delle immagini di copertina!
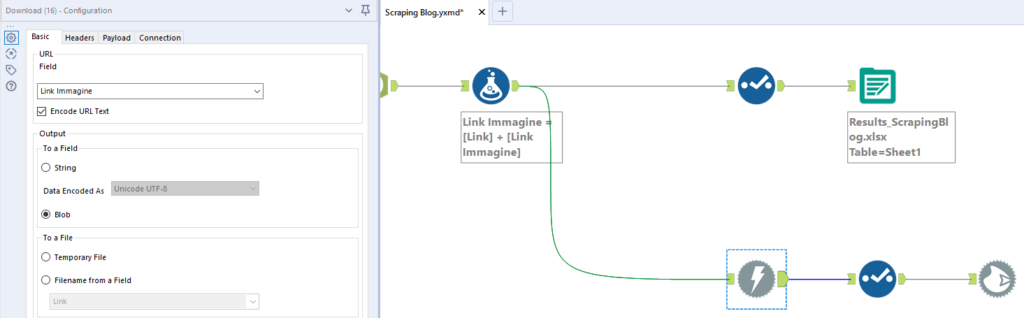
Trasciniamo un altro Download tool e lo colleghiamo al Formula tool precedente, configurandolo come nello screen shot qui sotto:
- Il campo che contiene l’URL è Link Immagine;
- Stavolta scegliamo Blob (Binary Large Object) come formato di output.
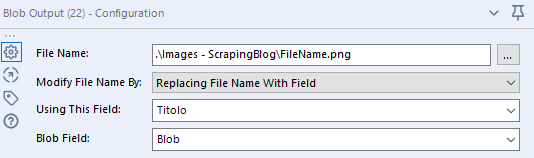
Ora non rimane che salvare le immagini. Posizioniamo il Blob Output tool sull’area di lavoro e lo configuriamo:
- Scegliamo la cartella di destinazione dell’output, specificando il nome e il formato del file;
- Selezioniamo una delle opzioni per rinominare i file (io ho scelto di dare alle immagini il nome del titolo);
- Specifichiamo il campo che contiene il Blob (in questo caso avevo rinominato, nel Select tool precedente, la colonna DownloadData proveniente dall’ultimo Download tool).
E il gioco è fatto! Abbiamo scaricato con successo le informazioni contenute nella pagina web. Ovviamente con questo flusso si potrebbe fare molto altro, come per esempio raccogliere i link ai singoli libri ed estrarre ulteriori informazioni, oppure ripetere il medesimo procedimento per ogni pagina di risultati.
Rimanete sintonizzati per non perdere la seconda parte di questo articolo, nella quale vedremo come fare lo scraping dei siti web che vengono generati lato client.
Seguitemi su Twitter, LinkedIn e Tableau Public per altre novità legate a Tableau e Alteryx.