Vai al contenuto
Vai al contenuto

Se seguite i nostri social network o se siete appassionati di ciclismo e del Giro d’Italia e leggete il “giornale rosa”, questa immagine qui sotto non dovrebbe risultarvi nuova:
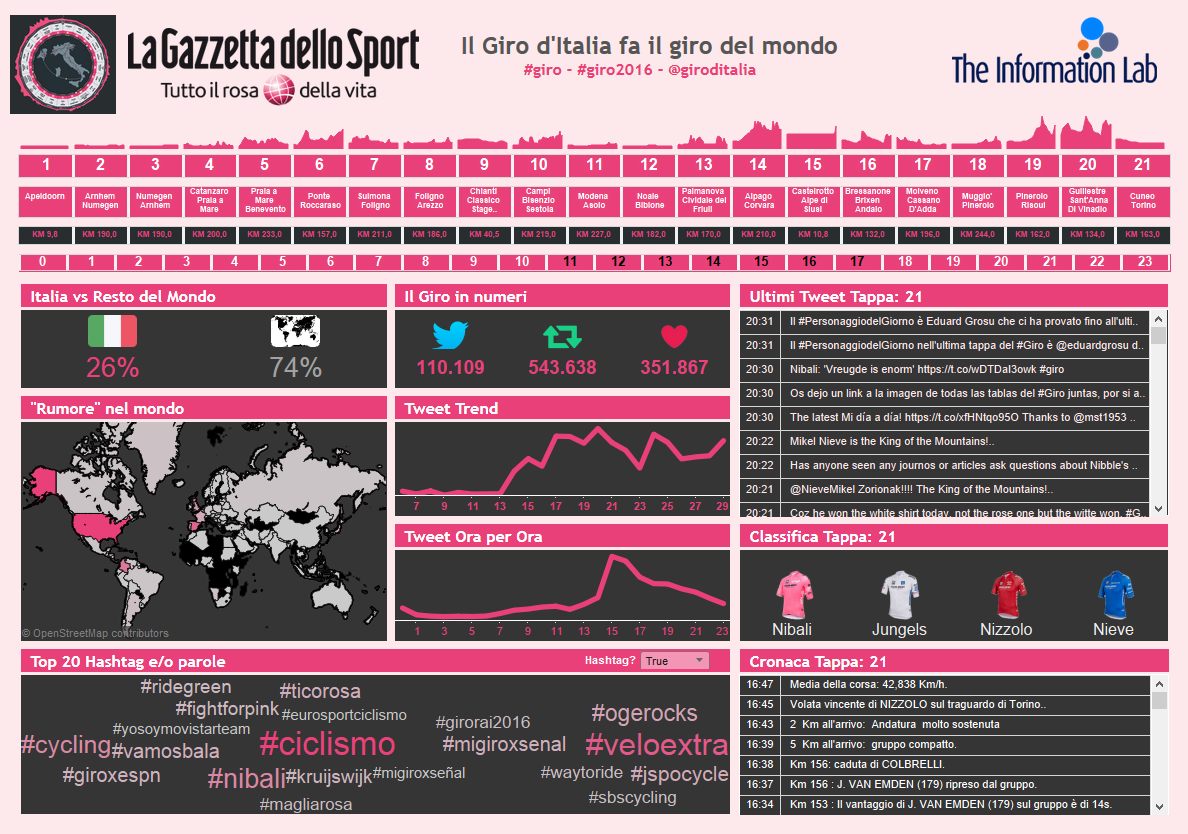
Abbiamo creato, in collaborazione con La Gazzetta dello Sport, un dashboard che riassume il Giro d’Italia visto e scritto dal popolo della rete. Cinguettii provenienti da qualsiasi parte del mondo dotata di connessione internet!
È possibile cliccare sul numero di una tappa e immediatamente si ha una panoramica sul numero di messaggi scritti, la provenienza e il trend ora per ora. Inoltre è anche possibile guardare in parallelo la cronaca minuto per minuto e i commenti scritti dagli utenti nello stesso periodo di tempo.
Oggi vorrei spiegarvi un po’ come è stato sviluppato questo dashboard, soffermandomi su un paio di punti che mi hanno messo a dura prova nella fase di cui mi sono occupata personalmente: il parsing dei dati.
Alcuni dei dati (come ad esempio la telecronaca minuto per minuto) ci sono stati forniti direttamente da Gazzetta, altri abbiamo dovuto reperirli dalla rete e poi unirli (blending) e farli “dialogare” tra di loro usando l’unico dato che li accumunava tutti: la data, l’ora e il numero di tappa.
Altitudini delle tappe
Ci piaceva l’idea di replicare il grafico ad area con i picchi delle altimetrie di ogni tappa:

PROBLEMA: non riuscivo a trovare da nessuna parte le cronotabelle con le quote delle altitudini di tutti i percorsi delle tappe. L’unica cosa reperibile in rete era un’immagine. Una jpeg per ogni tappa. Avrei dovuto copiare a mano 21 tappe, alcune delle quali toccavano più di 20 località per tappa!
Ho scaricato tutte le jpeg sul Google Drive, in attesa di trovare una soluzione… e la soluzione non ha tardato ad arrivare. Cliccando sull’immagine direttamente da drive c’era l’opzione per aprire la jpeg con Google Docs, l’editor di testo. Vuoi vedere che i google docs supportano il riconoscimento ottico (OCR)? Sì! Bingo!
Ho aperto tutte le jpeg con docs e ho salvato 21 file .txt che avevano questa “forma”:
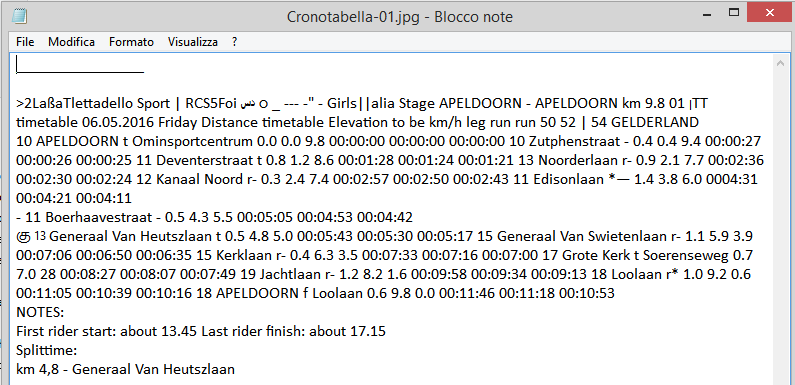
E spero che nessuna forma si senta offesa ad essere paragonata a questo ammasso senza senso di caratteri!
Però ad un’analisi più attenta questo testo non è completamente senza senso, senza logica. Quello che a me interessava recuperare era l’altitudine e il nome della località:
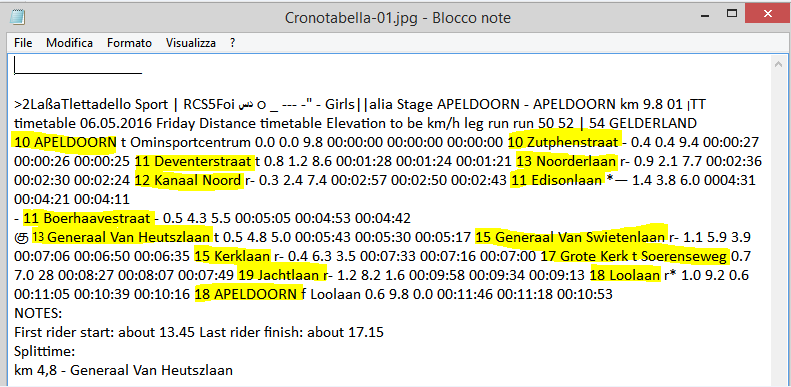
Non vi sembra che abbiano qualcosa in comune? Non vi sembra che ci sia un “pattern” che accomuna tutte le altitudini? Sì. Si tratta sempre di un numero, seguito da uno spazio e seguito da una parola.
Spazio-numero-spazio-parola. È un pattern. Ci vengono in aiuto le espressioni regolari e il RegEx Tool di Alteryx.
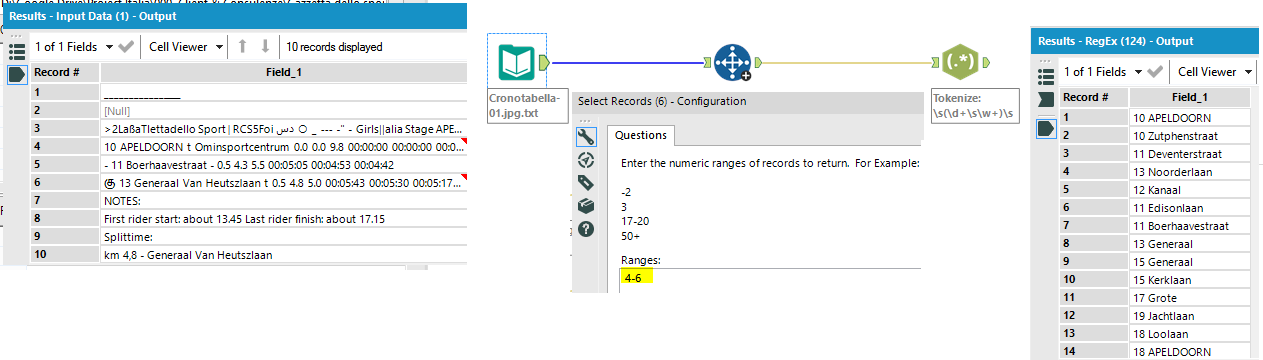
Una volta aperto il file di testo con l’Input Tool, ho usato un Select Records per selezionare solo le righe di interesse (dalla 4 alla 6) e poi ho impostato l’espressione regolare nel RegEx Tool:
Spazio-numero-spazio-parola-spazio = \s(\d+\s\w+)\s
- spazio –> \s
- 1 o più numeri –> \d+ (una successione di numeri)
- spazio –> \s
- parola –>\w+ (una successione di lettere dell’alfabeto)
- spazio –> \s
Creiamo un gruppo (marked group) mettendo tra parentesi solo quello che effettivamente ci interessa e selezioniamo come metodo il Tokenize to Rows, per creare una riga per ogni occorrenza del pattern.
E voilà! La magia è fatta!
Impostato il workflow una volta, l’ho usato anche per le altre 20 tappe.