 Vai al contenuto
Vai al contenuto

In questo articolo vogliamo rinfrescare i concetti principali e le basi di Snowflake, e più in generale della gestione dei dati su un data warehouse. Iniziamo quindi rispondendo alla domanda:
Cosa è Snowflake?
Snowflake è principalmente un data warehouse basato sul cloud. Può essere utilizzato anche come data lake, se necessario e permette agli utenti di accedere a più database da più locations.
- Data Warehouse: si tratta di un insieme di database in cui è possibile conservare diversi tipi di dati, provenienti da diverse fonti. Ogni utente può essere proprietario di diversi warehouse.
- Database: un archivio di dati strutturato, contenente diverse tabelle, che a loro volta contengono righe e colonne di dati strutturati
- Data Lake: un repository in cui vengono archiviati dati strutturati e non strutturati di grandi dimensioni prima di essere portati all’interno di un data warehouse. La differenza tra un Data Lake e un Data Warehouse consiste nella struttura dei dati archiviati, grezzi e non elaborati nel primo caso, elaborati e strutturati nel secondo.
Snowflake supporta tre piattaforme: AWS (Amazon Web Services), Azure e GCP (Google Cloud Platform).
Nel momento in cui ci si iscrive ad un account Snowflake, è necessario scegliere quale data cloud provider utilizzare, così come la Region. Inoltre, Snowflake è Clould Agnostic, ciò significa che i dati possono essere duplicati e/o distribuiti su più regioni.
A cosa serve Snowflake?
Snowflake è stato costruito dal cloud per il cloud. Per utilizzare Snowflake non è necessario installare, configurare o gestire un hardware o software.
Uno dei vantaggi principali dell’essere basato sul cloud consiste nella possibilità di superare alcuni dei problemi che possono essere comuni ad altri data warehouse basati sul cloud, come le prestazioni e la velocità.
Se infatti abbiamo la necessità di caricare dati più velocemente o eseguire un numero elevato di query in contemporanea, è possibile scalare il virtual warehouse per gestire le diverse richieste.
- Scaling up / down: processo che permette di aumentare o diminuire il numero di server all’interno di un unico cluster. Lo scaling up fornisce quindi più risorse computazionali quando vengono eseguite query più complesse, viceversa quando la domanda scende, si ridimensiona (scaling down). Deve essere eseguito manualmente.
- Scaling out / in: questo processo, chiamato anche Multi-Clustering, consiste invece nel potenziare il warehouse, aggiungendo dei cluster ulteriori. Grazie all’opzione di Auto-Scale, è possibile gestire dinamicamente e in modo ottimale il lavoro del warehouse, suddividendolo in modo da permettere a Snowflake di svolgere più attività contemporaneamente.
Si comprende quindi come questa flessibilità permetta di aumentare o diminuire le dimensioni del warehouse in base alle proprie esigenze. Questa caratteristica si traduce anche in un maggiore controllo dei costi, in quanto permettte di pagare solamente per quanto si è effettivamente utilizzato.
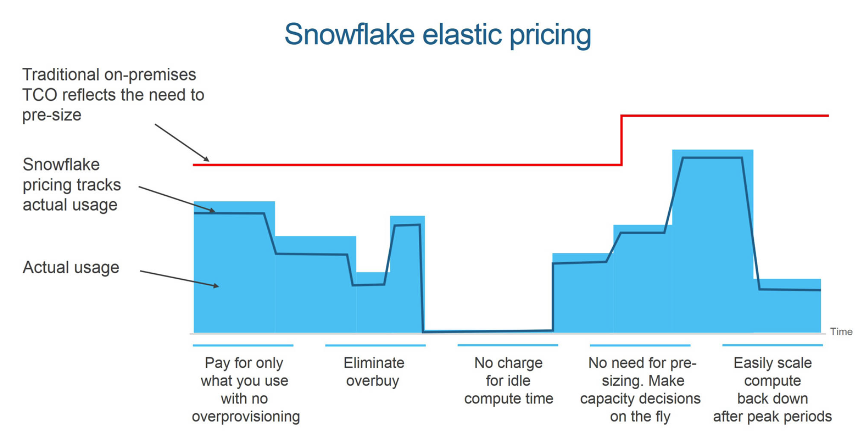
Un altro grande vantaggio di Snowflake riguarda l’accessibilità ai propri dati. È possibile infatti archiviare i dati in diverse availability zones, AWS, Azure o GCP. Nonostante questi server siano localizzati in punti specifici del globo, non è necessario trovarsi nelle vicinanze per archiviare e accedere ai dati: si può utilizzare una qualsiasi delle availability zones, indipendentemente dalla posizione. Tuttavia, è consigliabile scegliere la zona territorialmente più vicina, per evitare ritardi nell’accesso ai dati. Un’altra prassi utilizzata dalle aziende consiste nella duplicazione dei propri dati e la successiva archiviazione in più zone.
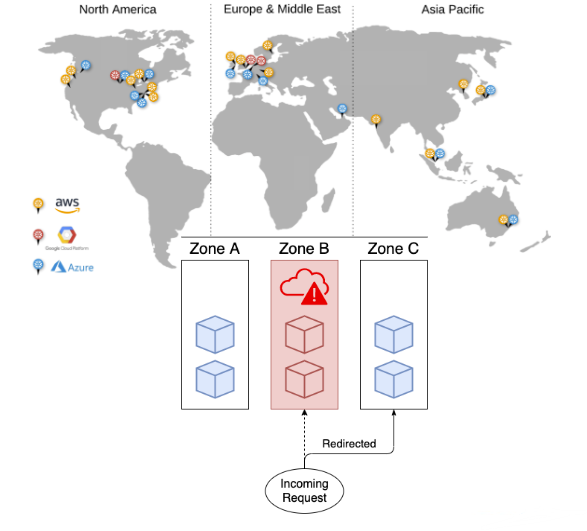
La funzionalità di condivisione dei dati di Snowflake consente alle aziende di condividere le tabelle con utenti esterni all’account: ad esempio una catena di retail è in grado di condividere i dati di vendita con i propri fornitori. Se in precedenza questo processo avveniva solitamente attraverso la condivisione manuale di file CSV, che portava spesso alla duplicazione di dati e uno spreco in termini di tempo e lavoro, ora avviene invece in termpo reale, riducendo le inefficienze.
Infine, Snowflake si basa sul concetto di **high availability (**o disponibilità). Questo concetto mira a garantire un livello concordato di prestazioni operative (il requisito di uptime) per un periodo di tempo superiore alla media.
Questa metrica – availability – misura quindi l’uptime di un servizio o il tempo in cui le operazioni vengono eseguite senza che si verifichi un errore di indisponibilità del servizio.
Viene solitamente calcolata come percentuale, ad esempio 99,9%, mensilmente, in base al rapporto tra i minuti di uptime del mese scelto e i minuti totali dello stesso mese. L’obiettivo è quello di evitare crash del sistema e perdita di dati (downtime).

La tabella 1 mostra la quantità di tempo in cui la risorsa può essere inattiva prima di infrangere il service level agreement (SLA) della disponibilità.
ELT vs ETL: qual è la differenza?
L’ETL è un processo in 3 fasi:
- Extract: estrazione dei dati da un sistema di origine. Ad esempio, i dati vengono estratti tramite l’accesso ad un database transazionale, sistemi CRM o logs/attività di un sito web.
- Transform – attività di blending, modellazione e trasformazione dei dati per ottenere informazioni. È qui che entrano in gioco i filtri e le aggregazioni. La granulalirità del dato viene mantenuta.
- Load – al termine dell’operazione di trasformazione, i dati vengono caricati nel DWH o nel Data Mart.
L’ETL è utilizzato dai sistemi più vecchi a causa della potenza e capacità di elaborazione limitate. Tuttavia, Snowflake predilige l’uso dell’ELT, che consente di caricare i dati nel cloud a un costo minimo ed eseguire le trasformazioni sulla piattaforma.
Come è composta l’interfaccia di Snowflake?
Worksheets (Fogli di lavoro): dove si scrivono le query SQL.
- SQL (Structured Query Language) – è un linguaggio informatico che consente di trasformare i dati all’interno di Snowflake.
Database: sono elencati sul lato sinistro; idealmente si dovrebbe creare un database diverso per ogni fonte di dati che arriva al data warehouse. È possibile impostare i ruoli all’interno di Snowflake e i successivi permessi per ciascun ruolo.
Schema: Un insieme di tabelle che contengono dati in relazione tra loro. Un database è un insieme di schemi.
Tabelle: in Snowflake ci sono tre tipologie di tabelle: temporanee, transitorie e permanenti:
- Tabelle temporanee: esistono solo all’interno della sessione in cui sono state create e persistono solo per il resto della sessione. Non sono visibili ad altri utenti o sessioni.Una volta terminata la sessione, i dati memorizzati nella tabella vengono eliminati completamente dal sistema e, pertanto, non sono recuperabili, ne’ dall’utente che ha creato la tabella, ne’ da Snowflake.
- Tabelle transitorie: persistono fino a quando non vengono esplicitamente eliminate e sono disponibili per tutti gli utenti con i privilegi appropriati. Sono progettate specificamente per i dati transitori che devono essere mantenuti in seguito ad ogni sessione (a differenza delle tabelle temporanee).
- Tabelle permanenti: (DEFAULT) simili alle tabelle transitorie, con la differenza fondamentale che hanno un periodo di Fail-safe. Questo fornisce un ulteriore livello di protezione e permette di recuperare i dati, che sono ad esempio stati eliminati erroneamente.
Viste: sono il risultato di una query SQL e possono essere visualizzate come in una tabella.
Database, tabelle e schemi sono oggetti Snowflake.
Trasformazione dei dati in Snowflake Snowflake ha anche la capacità di trasformare i dati e di generare viste all’interno del server Snowflake utilizzando l’ELT. Questo risultato può essere raggiunto scrivendo query SQL all’interno dei fogli di lavoro.
Connessione a Snowflake in Tableau Desktop È possibile collegare Tableau a Snowflake, tramite il pannello delle connessioni, nella sezione ‘Server’. Facendo clic su Snowflake si aprirà la finestra sottostante:
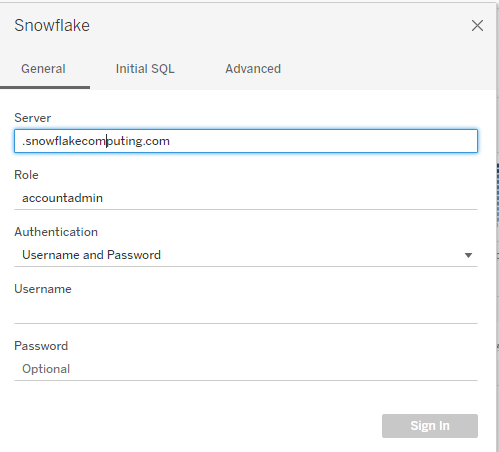
Il server sarà l’indirizzo URL del vostro Snowflake (i dettagli sono stati bloccati per sicurezza), tralasciando il prefisso https.
Si aprirà una finestra di autenticazione in cui si dovranno reinserire le proprie credenziali. Una volta fatto questo, Tableau chiederà di selezionare il Warehouse, il Database e lo Schema da cui è possibile selezionare e mettere in relazione le tabelle.
In questo modo si stabilirà automaticamente una connessione live, ma si potrà generare un estratto. Ricordate che ogni connessione o query ha un costo e quindi gli estratti possono essere un modo economico per costruire dashboard e scrivere calcoli prima di passare alla versione live.
Per connettersi a Snowflake utilizzando Alteryx, è necessario il driver ODBC. È possibile trovarlo tramite l’opzione Download dell’icona Help e dovrebbe essere scaricato dal repository di Snowflake.
Per ulteriori domande su Snowflake ti invitiamo a contattarci all’indirizzo: info@theinformationlab.it
Speriamo che questo articolo ti abbia incuriosito e che continui a seguire il nostro blog.
Alla prossima!

