 Vai al contenuto
Vai al contenuto

Abbiamo già visto nell’articolo dedicato al Dynamic Input Tool come sia possibile aprire tutte le tab che fanno parte di uno stesso file excel, senza dover ricorrere a tanti Input Tool.
Uno degli errori che più spesso Alteryx ci restituisce utilizzando il Dynamic Input è relativo allo schema delle tabelle:

The file XXX has a different schema than the 1st file in the set.
Quando succede ciò, significa che una delle tabelle/tab che stiamo provando ad aprire ha uno schema diverso (header di colonna e/o tipo di dato) rispetto alla prima dell’elenco che abbiamo fornito.
Magari questo file excel è il risultato di una lavorazione eseguita da qualcuno prima di noi, che si è preso in carico il compito di estrarre dai database i dati delle 3 regioni e di racchiuderli in uno stesso file excel, non accorgendosi dell’errore.
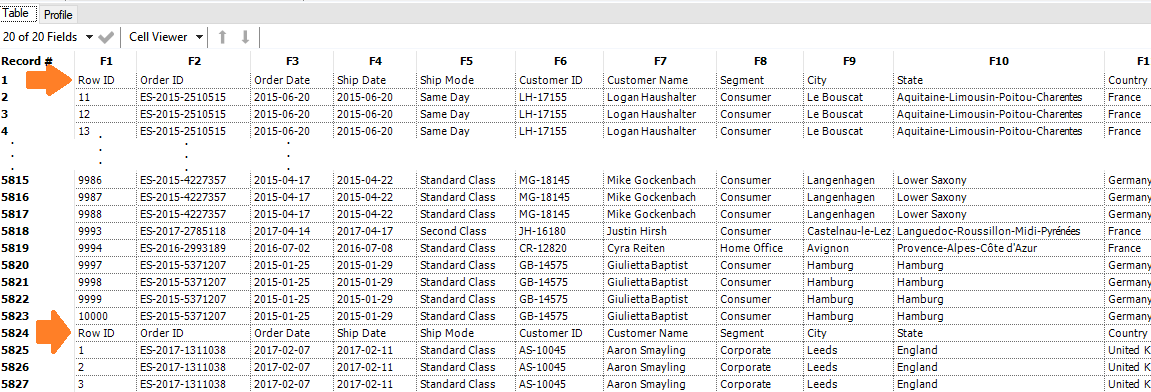
Potremmo aprire le 3 tab e andare alla ricerca della/e colonna/e differente/i. Nel mio caso è semplice, l’errore si nota dall’allineamento a sinistra dei numeri:
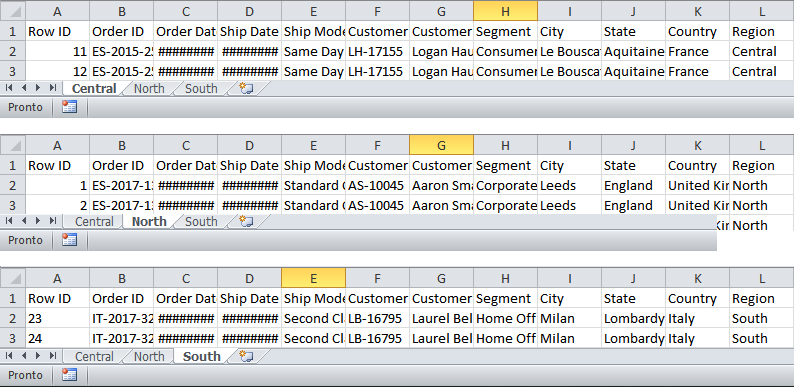
La colonna Row ID della tab South è un numero, mentre nelle altre due tab è un testo.
Ora cha abbiamo scoperto il problema, potremmo aprire il file excel e forzare il formato della colonna in stringa.
Questa operazione però ci porta via del tempo per “investigare” quali siano le colonne colpevoli e dell’ulteriore tempo per andare a modificare il file excel originale.
Potremmo in teoria anche chiamare chi ci ha fornito questo file e chiedere di investigare lui sui danni che ha combinato creando il file, ma questo ci obbligherebbe a stoppare il lavoro per aspettare la nuova versione del file.
Possiamo utilizzare però lo stesso Alteryx per saltare a “pié pari” il problema e andare avanti col nostro lavoro e, perché no, creare un flusso che faremo girare mensilmente in automia grazie a delle schedulazioni. Quindi un qualcosa che funzioni da solo e sempre, indipendentamente dalla sbadataggine di chi ci fornisce i file!
Ragioniamo su come funziona il Dynamic Input:
- apre in modo sequenziale tutte le tab che fanno parte dello stesso excel
- esegue una union per appendere le tab una sotto l’altra
- la union non funziona perché la colonna RowID di una delle tab è un numero mentre nelle altre un testo
Esisterà un modo per fare in modo che Alteryx in apertura converta tutte le colonne di tutte le tab in stringa?
La stringa può contenere sia testi che numeri che date, può contenere tutto: avendo tutte stringhe risolveremmo il problema del diverso data type senza compromettere il contenuto delle celle!
Un file di excel si può considerare un file strutturato. E’ possibile deciderne il formato delle colonne e Alteryx in fase di connessione leggerà ciò che è stato impostato in excel, mantenendo dunque il formato originale:
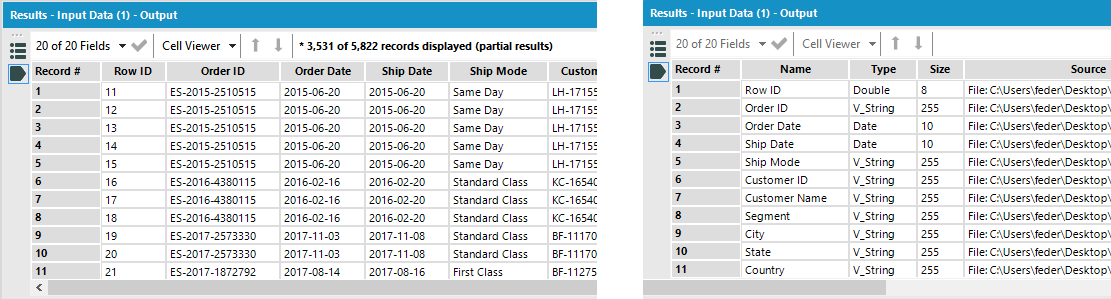
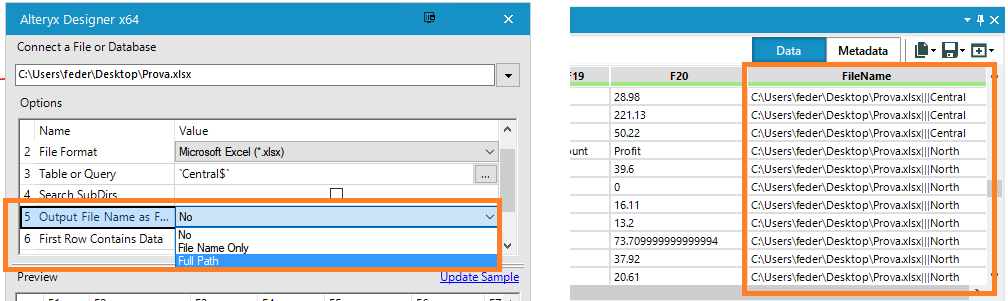
Tra le varie opzioni dell’Input Tool però, ne abbiamo una per dire al tool che la prima riga dell’excel (A1, B1, C1, D1, ecc, ecc, ecc…) contiene dei dati.
Solitamente in excel la prima riga contiene i titoli delle colonne e i dati veri e propri della tabella iniziano dalla riga 2. Questa opzione è utile qualora l’excel fosse sprovvisto di titoli. Ma ci torna utile anche per il nostro scopo.
Selezionandola infatti, faremo slittare i titoli di colonna nel Record#1, (tra i dati) e Alteryx imposterebbe dei generici F1, F2, F3, ecc, ecc, ecc… come titoli di colonna.
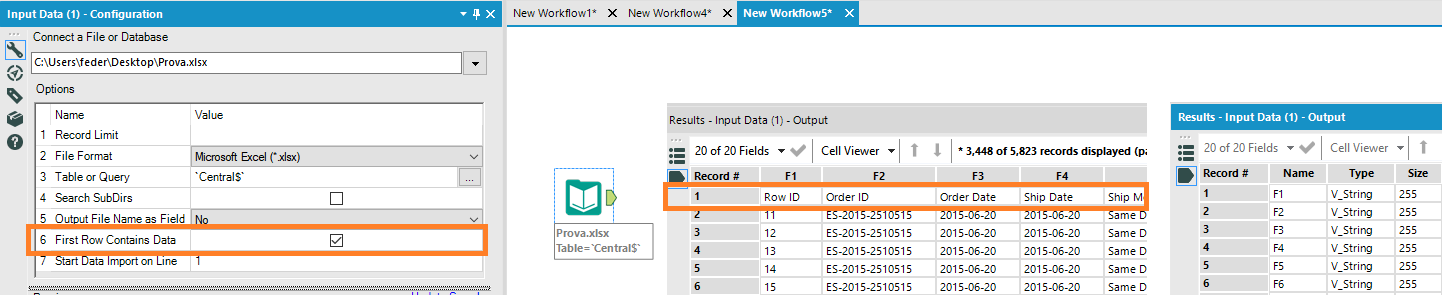
Avendo inglobato gli header (dei testi) tra i dati della tabella, Alteryx è OBBLIGATO a cambiare il data type in stringa e lo fa per tutte le colonne!
Se quindi ci ricordiamo di attivare l’opzione numero 6 quando andiamo a decidere il template del Dynamic Input, non avremo più quell’errore iniziale.
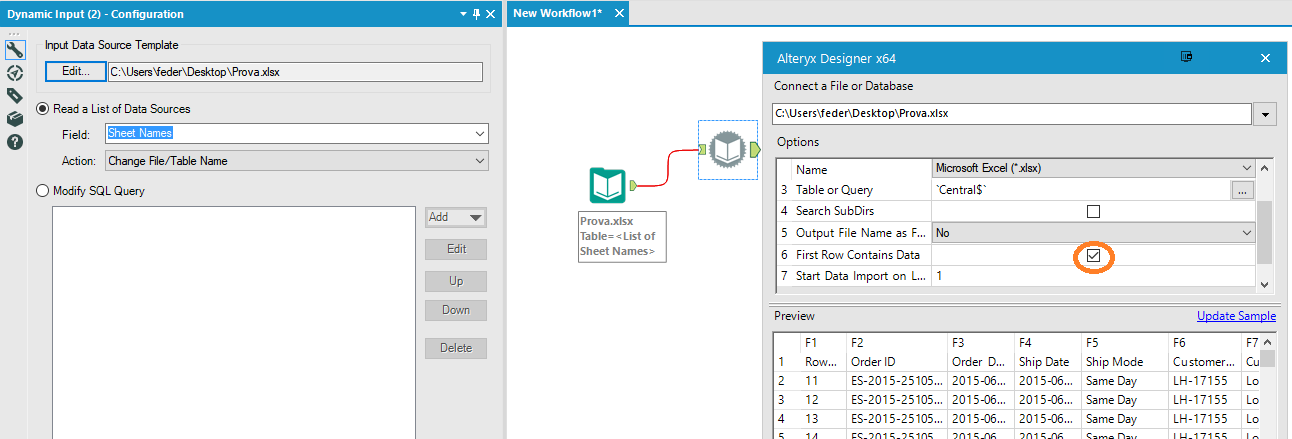
Abbiamo risolto un problema, ma ce ne siamo creati un altro.
Lo slittamento dei titoli come prima riga di dati varrà per ogni tab aperta, il che significa che se abbiamo aperto 3 tab, avremo 3 righe di dati che contengono gli header e che non ci serviranno, perché non sono dati da studiare:
Nello specifico sarà la prima riga di ogni tab quella inutile che contiene i titoli. Possiamo quindi “skippare” il primo record di ogni tab, ad esempio con un Sample Tool.
Ma come facciamo a sapere a che foglio di lavoro/tab appartiene ogni riga? Possiamo farci stampare una colonna con il nome della tab di provenienza direttamente nella scelta del template del Dynamic Input:
Ora possiamo impostare il Sample Tool:
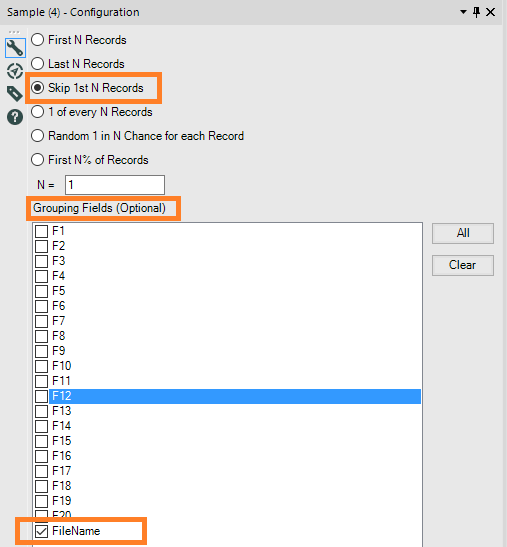
Quindi il tool raggrupperà tutte le righe che fanno parte dello stesso FileName ed escluderà la prima riga.
Ora abbiamo un secondo problema: non abbiamo più i titoli di colonna, perché li abbiamo appena esclusi. Li possiamo però recuperare dal Dynamic Input utilizzando un Sample Tool ancora, ma questa volta tenendo solo la prima riga in assoluto:
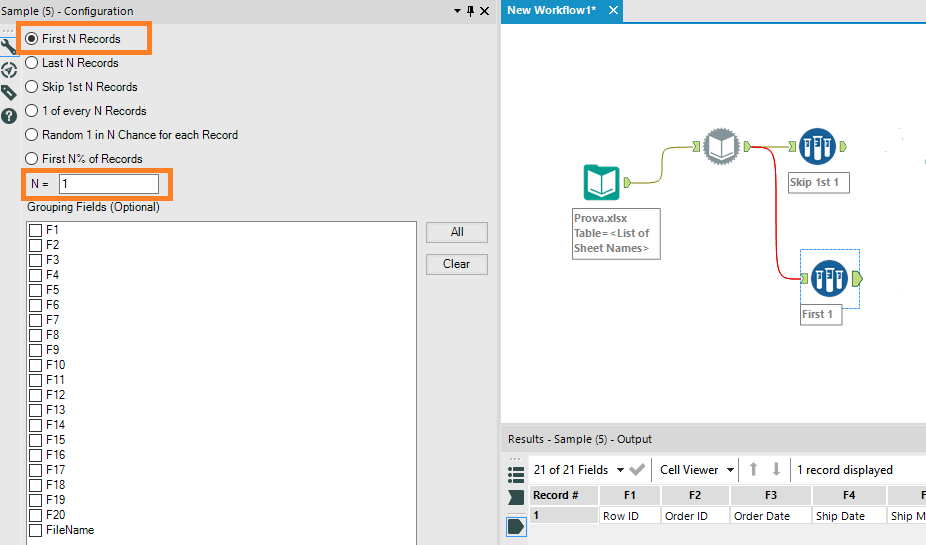
Se ora ribaltiamo la tabella che abbiamo (Transpose Tool) ci creiamo una tabella di lookup che ci permetterà di rinominare la tabella del flusso superiore in modo dinamico:
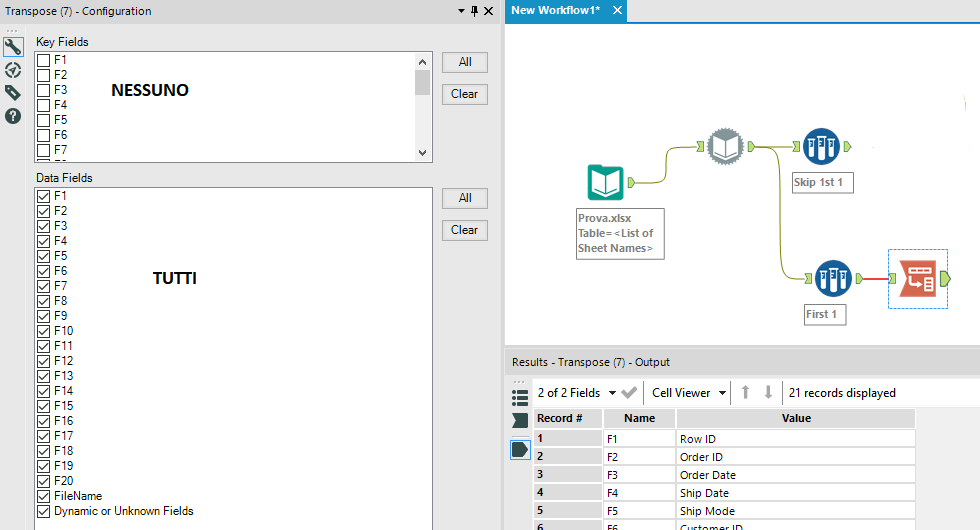
Ora possiamo completare il nostro workflow utilizzando un Dynamic Rename e un Autofield che andrà a settare il giusto tipo di dato per ogni colonna:
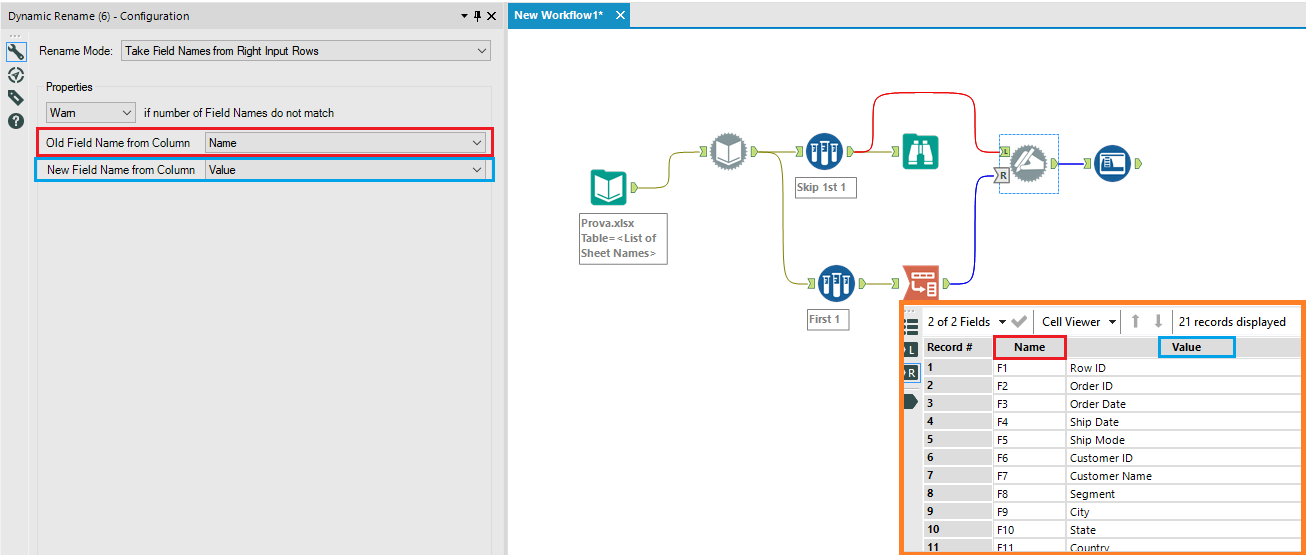
Con una manciata di tool siamo riusciti ad aprire delle tab di excel che avevano delle colonne impostate con data type differenti.
Dato che selezionando l’opzione 6 del template obblighiamo Alteryx ad utilizzare degli header fittizzi (F1, F2, F3, F4, F5, ecc, ecc…) questa procedura funziona anche se l’errore del Dynamic Input different schema non è dato da una colonna con data type diverso, ma da una colonna con titolo diverso dalle altre. Diventando tutte “FNumero”, Alteryx sarà in grado di incolonnare le colonne nel modo giusto.
Dovete però essere sicuri che le colonne, pur chiamandosi in modo diverso, siano nella stessa posizione/sequenza.
PS: questa procedura protrebbe non funzionare se tra i titoli di colonna originali ce n’è uno che è un numero. In questo caso Alteryx potrebbe non aver nessuna ragione di cambiare il data type.
[button URL=”https://pages.alteryx.com/free-trial.html?partner_lead_src=WebsiteFreeTrial&partner_id=A209452&crp=A209452″]Download Alteryx[/button] [button URL=”https://www.theinformationlab.it/newsletter-2/”]Iscriviti alla newsletter[/button]

