 Vai al contenuto
Vai al contenuto

Sankey Charts, forse non sapete cosa sono ma molto probabilmente ne avrete vista almeno una qua e la sulla viz gallery di Tableau. Una Sankey charts o un diagramma Sankey ci permette di visualizzare relazioni e flussi tra molteplici elementi e tipicamente sono utilizzate al meglio quando vogliamo mostrare il flusso all’interno di un sistema. Per farvi capire meglio di cosa sto parlando, utilizzerò il file Sample Superstore, fornito di base nella cartella My Tableau Repository > Datasources.
[tableau url=”https://public.tableau.com/views/SimpleSankey/Sankey?:embed=y&:display_count=no&:showTabs=y” width=”650px” height=”800px”][/tableau]
Ok, sono molto belle ma forse alcuni non riuscirebbero a capirle a pieno, perchè difficili da leggere. Quindi, usatele con parsimonia e se avete alternative più semplice ma più comprensibili per tutti, sapete cosa fare.
Come si costruiscono? Seguiremo l’esempio di Chris Love di The Information Lab UK.
Passo 1: Duplichiamo i dati
Abbiamo bisogno di duplicare i nostri dati e creare un nuovo campo che ci dica se ci stiamo riferendo ai dati Originali o alla Copia. Ci sono vari modi per farlo, con Alteryx, copia e incolla in Excel, con il Legacy Connector. Siete liberi di scegliere quello che volete.
Siccome stiamo usando un file Excel, proviamo il Legacy Connector.
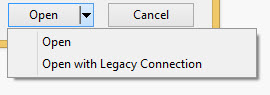
Dopodiché converto il mio foglio Orders in Custom SQL, in questo modo:
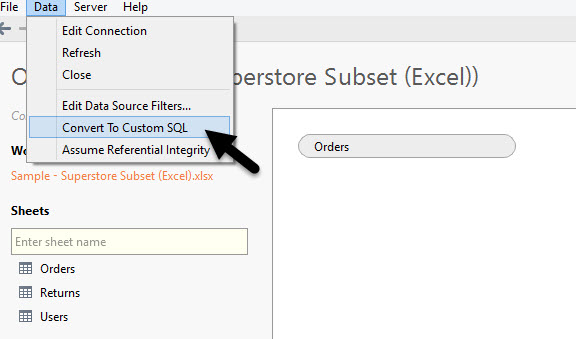
Questo qua sotto è il codice da copiare e incollare, in rosso il campo creato da zero per distinguere le Copie dagli Originali
SELECT [Orders$].[City] AS [City],
[Orders$].[Customer ID] AS [Customer ID],
[Orders$].[Customer Name] AS [Customer Name],
[Orders$].[Customer Segment] AS [Customer Segment],
[Orders$].[Discount] AS [Discount],
[Orders$].[Order Date] AS [Order Date],
[Orders$].[Order ID] AS [Order ID],
[Orders$].[Order Priority] AS [Order Priority],
[Orders$].[Postal Code] AS [Postal Code],
[Orders$].[Product Base Margin] AS [Product Base Margin],
[Orders$].[Product Category] AS [Product Category],
[Orders$].[Product Container] AS [Product Container],
[Orders$].[Product Name] AS [Product Name],
[Orders$].[Product Sub-Category] AS [Product Sub-Category],
[Orders$].[Profit] AS [Profit],
[Orders$].[Quantity ordered new] AS [Quantity ordered new],
[Orders$].[Region] AS [Region],
[Orders$].[Row ID] AS [Row ID],
[Orders$].[Sales] AS [Sales],
[Orders$].[Ship Date] AS [Ship Date],
[Orders$].[Ship Mode] AS [Ship Mode],
[Orders$].[Shipping Cost] AS [Shipping Cost],
[Orders$].[State or Province] AS [State or Province],
[Orders$].[Unit Price] AS [Unit Price],
‘Copia’ as Nuovo Campo
FROM [Orders$]
UNION
SELECT [Orders$].[City] AS [City],
[Orders$].[Customer ID] AS [Customer ID],
[Orders$].[Customer Name] AS [Customer Name],
[Orders$].[Customer Segment] AS [Customer Segment],
[Orders$].[Discount] AS [Discount],
[Orders$].[Order Date] AS [Order Date],
[Orders$].[Order ID] AS [Order ID],
[Orders$].[Order Priority] AS [Order Priority],
[Orders$].[Postal Code] AS [Postal Code],
[Orders$].[Product Base Margin] AS [Product Base Margin],
[Orders$].[Product Category] AS [Product Category],
[Orders$].[Product Container] AS [Product Container],
[Orders$].[Product Name] AS [Product Name],
[Orders$].[Product Sub-Category] AS [Product Sub-Category],
[Orders$].[Profit] AS [Profit],
[Orders$].[Quantity ordered new] AS [Quantity ordered new],
[Orders$].[Region] AS [Region],
[Orders$].[Row ID] AS [Row ID],
[Orders$].[Sales] AS [Sales],
[Orders$].[Ship Date] AS [Ship Date],
[Orders$].[Ship Mode] AS [Ship Mode],
[Orders$].[Shipping Cost] AS [Shipping Cost],
[Orders$].[State or Province] AS [State or Province],
[Orders$].[Unit Price] AS [Unit Price],
‘Originale’ as Nuovo campo
FROM [Orders$]
Una volta fatto, li uniamo con una Union, in modo da avere un solo foglio.
Passo 2: Addensiamo i dati con dei Bins
Creiamo una nuova misura, la chiamiamo ToPad (imbottire ndr)
if [Nome Nuovo campo]==’Originale’ then 1 else 49 end
Se il campo che abbiamo aggiunto, che definisce se un dato è Originale o una Copia, allora fai 1 altrimenti 49
E creiamo i Bin ora, di dimensione 1. Clicchiamo col tasto destro su ToPad e facciamo Create Bins, dandogli il nome Padded (imbottito ndr)
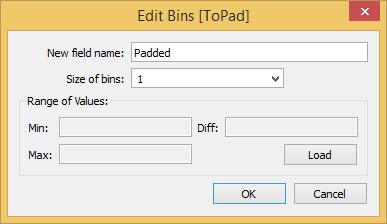
In questo modo abbiamo creato 49 righe di dati per ogni riga originale. Vediamo se ha funzionato creando una terza funzione, che chiameremo [t]:
[t]=(index()-25)/4
Ora mettiamo [t] sulle colonne e il nostro campo Padded con i bin in Detail. Cambiamo i mark in Circle ed infine assicuriamoci che [t] sia computato su Padded.
Dovrebbe uscirvi così

L’addensamento è avvenuto, l’index() ha computato sui bins e ha creato dei valori che prima non c’erano. Ora, cosa si possa fare con questi nuovi valori è roba da jedi, per ora continuiamo con il nostro esercizio.
Passo 3: Costruiamo la nostra funzione per il Ranking
Ora ci serve una funzione che mostri i nostri dati al punto giusto, verticalmente, quando creiamo le nostre Sankey
[Rank 1] = RUNNING_SUM(sum(Sales))/TOTAL(sum(Sales))
[Rank 2] = RUNNING_SUM(sum(Sales))/TOTAL(sum(Sales))
Creano un running total di Sales e lo dividono per il Total, fornendoci una percentuale cumulativa.
Passo 4: Costruire la nostra funziona per la Curva
Utilizzeremo la funzione di sigma che ci darà la curva
[Sigma] = 1/(1+EXP(1)^-[t])
e aggiungiamo la curva
[Curva] = [Rank 1]+(([Rank 2] – [Rank 1])*[Sigma])
Passo 5: Costruiamo la visualizzazione
Trascinate due dimensioni in Detail, queste saranno la nostra parte Destra e quella Sinistra del diagramma di Sankey. Chris usa due parametri in modo che la scelta sia sempre dinamica e sia il fruitore finale a scegliere e cambiare le dimensioni in gioco.
Aggiungete [Curva] alle righe e ora dobbiamo passare a parlare di Nested Table Calc (calcoli in tabelle nidificate, se volete farvi una cultura leggete questo articolo di Nelson Davis, uno Zen Master). Il calcolo della nostra [Curva] è composto da 3 parti, [Rank 1], [Rank 2] e [t] e abbiamo bisogno che ognuna di esse si indirizzi verso una diversa dimensione. Vogliamo avere un Rank di entrambe le dimensioni ma vogliamo anche ogni calcolo del Rank in un ordine diverso, perchè vogliamo che Rank 1 sia ordinato dalla dimensione di sinistra per prima e che Rank 2 sia ordinato dalla dimensione di destra. In questo modo il flusso sembrerà corretto.
Per fare ciò clicchiamo con il tasto desto su [Curva] che avevamo parcheggiato in righe. Selezionamo Edit Tableau Calculation. Sistemiamo Rank 1 per primo, cliccate su Advanced e scegliete le opzioni qua sotto
![]()
Ora facciamo lo stesso per Rank 2 ma con ordine diverso delle Dimensioni. Scegliamo Rank 2 dal menu a tendina
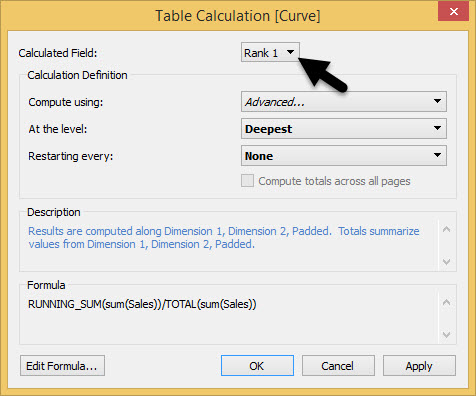
Cambiamo quindi l’ordine delle dimensioni scelte coi parametri. Prima la 2 e poi la 1
![]()
Ultima cosa, scegliamo [t] e la computiamo semplicemente su Padded
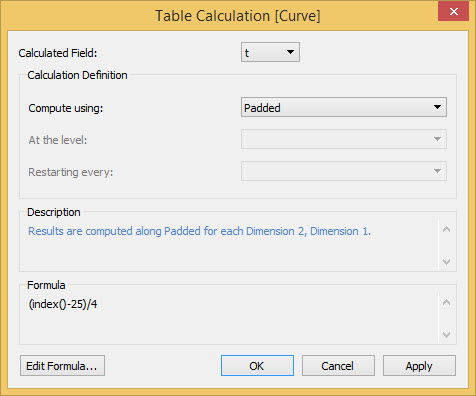
Il risultato finale sarà questo
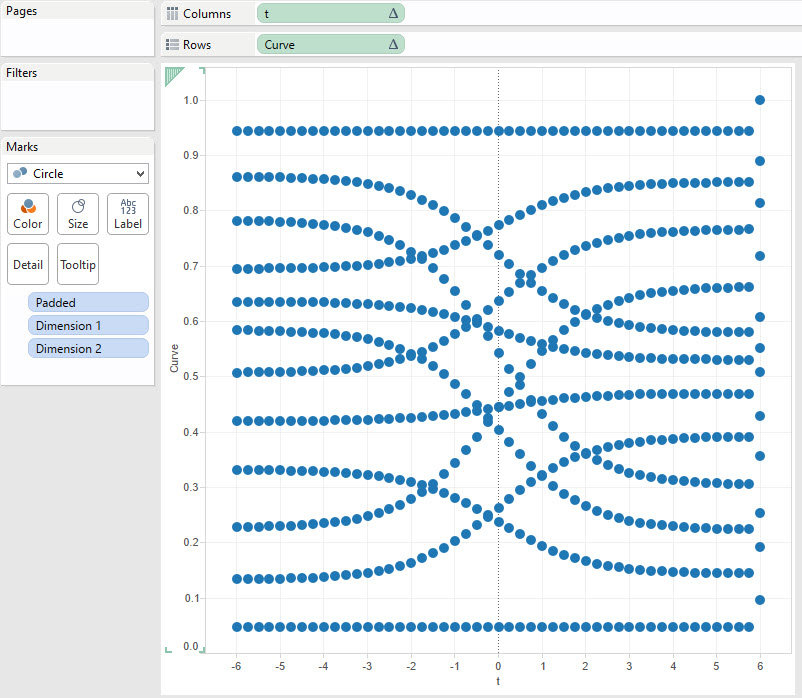
Passo 7: Ordiniamo e abbelliamo
Leviamo tutte le griglie, le linee dello 0, nascondiamo gli assi e diamo un po’ di colore inserendo Region nel Marks dei colori, così che ogni linea sarà colorata per regione. Cosa più importante però è sistemare quei pallini uno dietro l’altro. Sistemiamo l’asse di [t] che vada da -5 a 5 e quello della [Curva] da 0 a 1, inoltre a quest’ultimo invertiamo l’asse. Come ultima cosa scegliamo Line dai marks e inseriamo Padded su Path.

Passo 8: diamo volume
Ora diamo volume alle linee in base alle vendite (Sales). Su usassimo un Sum([Sales]) su Size non funzionerebbe, quindi useremo una Table Calculation così:
RUNNING_AVG(SUM([Sales]))
Ora aggiungiamolo a Size e computiamo su Padded. Scegliete la grandezza che preferite.

Passo 9: Aggiungiamo le dimensioni
Ora basterà costruire due grafici singoli, di tipo bar stacked che mostrino la percentuale di Sales per ogni dimensione. Ora unite tutto in una sola dashboard con le due colonne ai lati e il flusso al centro.
[tableau url=”https://public.tableau.com/views/SimpleSankey/Sankey?:embed=y&:display_count=no&:showTabs=y” width=”650px” height=”800px”][/tableau]
Grazie per la lettura e nella speranza che sia stato tutto chiaro, vi rimandiamo al nostro account Twitter, per dubbi, approfondimenti e domande varie @infolabIT

