 Vai al contenuto
Vai al contenuto

Supponiamo di avere una lookup table con delle descrizioni e dei codici normalizzati, che devono essere assegnati ai nostri dati. Ad esempio Il nostro collega scrive le descrizioni degli immobili tutti abbrevviati e sempre in modo diverso. A noi tocca l’onere di dover assegnare i giusti codici castali.
Esiste un modo per far sì che le descrizioni “ABIT.CIVILI”, “ABITAZIONI CIVIL.” e “A/2 – AB. CIVILI” vengano tutte riconosciute come “A/2 – Abitazioni di tipo civile”?

Un modo potrebbe essere tramite una condizione IF. Ci copiamo tutte le nostre descrizioni “sballate” e con calma ci mettiamo a scrivere la nostra funzione:
IF [Descrizione] in (“ABITAZIONE TIPO CIVILE”, “ABIT. CIVILE A/2”) or Contains([Descrizione], “APPARTAMENT”) then “Abitazioni di tipo civile” else ecc, ecc, ecc…
Dobbiamo fare uno studio su tutte le diverse etichette che può assumere uno stesso immobile e costruire la funzione condizionale di modo che tutte le condizioni simili ci restituiscano lo stesso risultato. Il nostro catasto prevede 53 differenti categorie di immobili… avremo come minimo 53 condizioni IF/ELSEIF!
E se domani il nostro collega si inventa una nuova abbreviazione non contemplata dal nostro calcolo condizionale? Resterà escluso e dovremo tornare a mettere mano alla nostra IF kilometrica!
Se la nostra tabella di lookup non è molto vasta, si può fare. Ma se vogliamo semplificarci la vita, possiamo utilizzare il Fuzzy Match.
Il Fuzzy Match è un tool di Alteryx che prevede tutta una serie di algoritmi per il riconoscimento di stringhe di testo, creati da persone molto più esperte di noi in materia, e suddivise in diverse categorie di testi (indirizzi, nomi, numeri di telefono….).
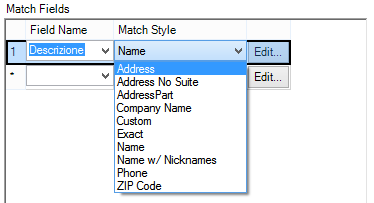
Possiamo utilizzare questi algoritmi così come sono o andare a modificare le soglie % di riconoscimento (e anche altre opzioni) per rendere l’algoritmo più o meno sensibile.
Dove sta il problema? Il tool praticamente fa un confronto tra le lettere in comune tra due differenti stringhe e le posizioni in cui si trovano e restituisce ad esempio solo le parole che hanno il 95% di somiglianza.
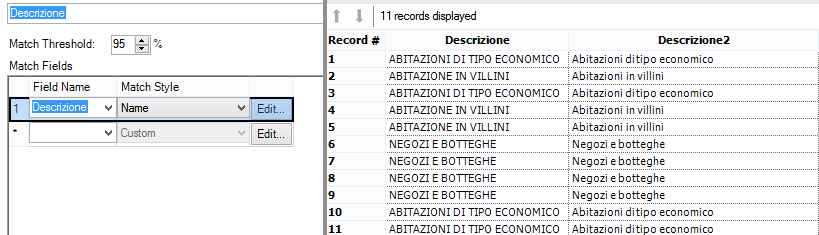
Se abbassiamo la soglia a 80%, verranno trovati molti più match, ma saranno sempre meno precisi:
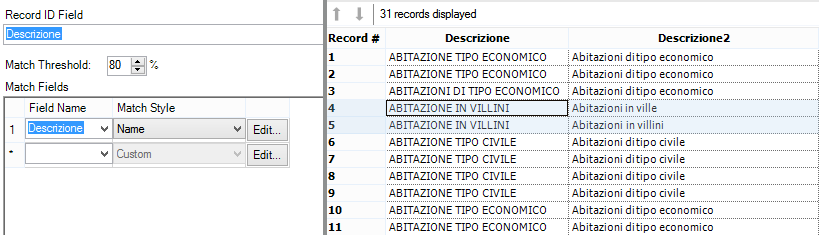
Siamo passati da 11 a 31 parole riconosciute, ma “Abitazioni in ville” e “Abitazioni in villini” sono talmente simili che il Fuzzy Match fa confusione e abbina alla stessa etichetta due decrizioni diverse. La soluzione?
Usare il Fuzzy Match a cascata. Si parte da una soglia piuttosto alta, si tolgono dal set di dati le etichette riconosciute con una Join con i dati originali e si continua con le etichette residue (che restano nel connettore R o L del Join tool) ripetendo il Fuzzy Match con soglie via via sempre più basse. In questo modo, con il primo Fuzzy Match al 95% abbiniamo e togliamo dal set di dati “ABITAZIONE IN VILLINI” e saremo liberi di abbinare col Fuzzy Match successivo all’80% l’etichetta ABITAZIONE IN VILLE, perché non ci sarà più l’etichetta “ABITAZIONE IN VILLINI” che creava confusione.
E si andrà avanti ad abbinare etichette/descrizioni a soglie % via via sempre più basse, finché non avremo abbinato tutto.
Nella realtà sarà pressoché impossibile trovare una soglia % che riesca ad abbinare tutte le voci nel modo giusto in un colpo solo, soprattutto se le etichette sono tante e si somigliano. Questa pratica di usare il Fuzzy Match a cascata è molto frequente.

