Vai al contenuto
Vai al contenuto

Ciao a tutti!
Rieccoci al nostro appuntamento settimanale della rubrica su Snowflake. 🙂
L’obiettivo di oggi è darvi una panoramica sui famigerati dati semi-strutturati! Vediamo insieme di cosa si tratta e soprattutto come gestirli su Snowflake.
Cosa sono i dati semi-strutturati
I cosiddetti dati semi-strutturati costituiscono quella enorme mole di dati generati in automatico provenienti da siti web o applicazioni, che sono meno strutturati dei formati tradizionali (come quelli csv o dei databases relazionali).
La differenza sostanziale fra i dati strutturati e quelli semi-strutturati è la mancanza di uno schema fisso per questi ultimi. Infatti, i dati semi-strutturati possono costantemente evolversi con l’aggiunta di nuovi attributi. Inoltre, possono contenere più informazioni annidate una nell’altra, a differenza dei dati strutturati che sono “piatti”.
Come gestirli su Snowflake
Uno dei grandi punti di forza di Snowflake è la possibilità di gestire i dati semi-strutturati in modo simile a quelli strutturati, senza il bisogno di grandi sforzi aggiuntivi!
- È possibile importare questo formato di dati in pochi minuti e visualizzarli come tradizionali tabelle: questo li rende più agevoli da leggere e da utilizzare anche da altri utenti.
- Si possono interrogare e modificare i dati semi-strutturati con SQL queries veloci ed efficienti.
- Si possono fare join con altre tabelle, sia di dati semi-strutturati che di dati strutturati.
Snowflake supporta 5 formati di dati semi-strutturati: JSON, Avro, ORC, Parquet e XML.
Vediamo nel dettaglio come si eseguono alcune delle operazioni citate.
Importare dati semi-strutturati su Snowflake
Su Snowflake si possono agevolmente importare dati semi-strutturati utilizzando il tipo di dato VARIANT.
Vediamolo per steps:
1. Selezionare o creare il database da utilizzare.
2. Creare una tabella con una singola colonna di tipo VARIANT. In questo modo, si utilizza un tipo di dato non definito, che può contenere valori di ogni tipo, inclusi OBJECT e ARRAY, spesso presenti nei semi-structured data. Si può poi successivamente convertire il VARIANT nel tipo corretto, tramite un’istruzione CAST
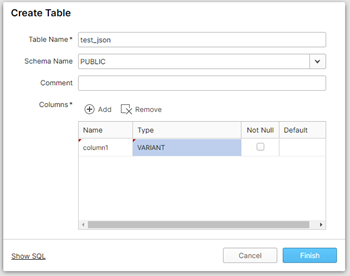
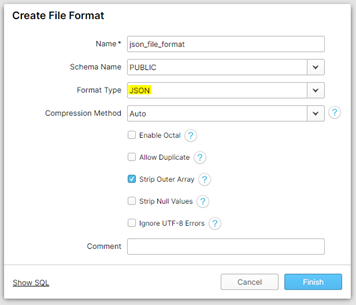
3. Creare un File Format, selezionando il tipo di formato che si andrà ad utilizzare (ad esempio JSON). In questa fase, è possibile selezionare alcune opzioni aggiuntive come rimuovere valori null (Strip Null Values) o rimuovere i caratteri extra (Strip Outer Array).
4. Selezionare la tabella creata dall’elenco delle tabelle presenti nel database, cliccare su Load Data.
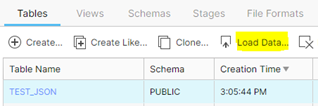
A questo punto seguire gli steps proposti dalla finestra di dialogo che si apre: selezionare il warehouse da utilizzare per eseguire la query, poi selezionare il file di origine o lo stage da cui caricare i dati, infine scegliere il File Format adatto. L’ultima voce, Load Options, è opzionale e permette di selezionare quale opzione eseguire in caso di errore nel caricamento.
5. Ora la tua tabella è popolata! I dati sono stati caricati e accanto al nome della tabella puoi vedere il numero di righe presenti.
Ricordiamo che i passaggi che abbiamo effettuato negli steps precedenti utilizzando una interfaccia user-friendly possono essere direttamente eseguiti scrivendo l’istruzione in SQL nella sezione Worksheets di Snowflake.
Per vedere il codice SQL sottostante alle operazioni appena eseguite basta cliccare su Show SQL nelle rispettive finestre di dialogo.
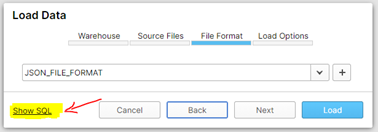
In particolare, il comando SQL per caricare dei dati in una tabella è un COPY INTO:
COPY INTO "NOME_DB"."NOME_SCHEMA"."TEST_JSON" //path completo della tabella da popolare
FROM @/ui1630052884594 //file da cui provengono i dati
FILE_FORMAT = '"NOME_DB"."NOME_SCHEMA"."JSON_FILE_FORMAT"'; //file format da usareManipolare dati semi-strutturati su Snowflake (video tutorial!)
Una volta che i dati sono stati caricati su Snowflake, vogliamo manipolarli per disporne in un formato tabellare più accessibile a tutti e facile da leggere.
Su Snowflake si dispone di un’ampia serie di comandi SQL proprio per gestire questo tipo di dati.
Abbiamo visto come farlo in pochi minuti con un esempio nel video tutorial di questa rubrica!
Se siete interessati ad approfondire l’argomento, vi consigliamo di dare un’occhiata alla documentazione Snowflake sui semi-structured data e su tutte le funzioni disponibili.
Per ulteriori domande su Snowflake vi invitiamo a contattarci all’indirizzo: info@theinformationlab.it
Speriamo che questo articolo vi abbia incuriosito e che continuiate a seguire il nostro blog.
Vi diamo appuntamento alla settimana prossima con un approfondimento sulla funzione Time Travel di Snowflake!
Alla prossima! ❄️